

DataFrame(データフレーム) とは、2次元の表形式のデータ構造です。pandas.DataFrame クラスを使います。
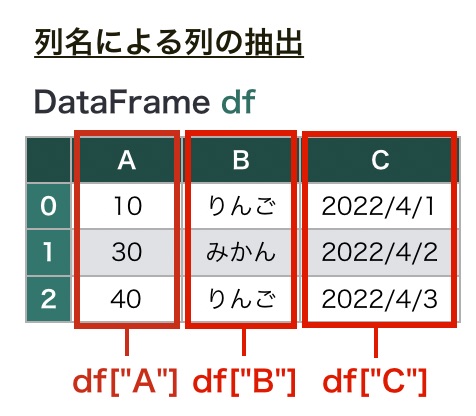
DataFrameの各行には行名が、各列には列名がふられており、これらの名前を使って特定の行・列にアクセスできます。たとえば、DataFrame型の変数 df があるとき、 df[“A”] のように書くと、列Aだけを抽出できます。
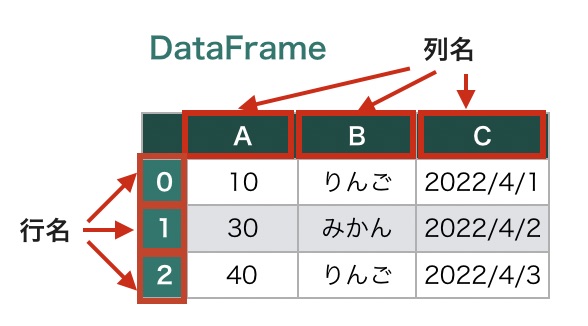
DataFrameは、次のように pd.DataFrame() にリストのリストを渡すことで作成できます。
import pandas as pd
# 3行3列のDataFrameを作成
df = pd.DataFrame([[10, "りんご", "2022/4/1"],
[20, "みかん", "2022/4/2"],
[30, "りんご", "2022/4/3"]],
columns=["A", "B", "C"]) # 列名の指定DataFrame型のオブジェクトには、「DataFrame」を略した df という変数名がよく使われます。
Series(シリーズ) とは1次元のデータ構造で、DataFrameの1列分のデータに相当します。 pandas.Series クラスを使います。
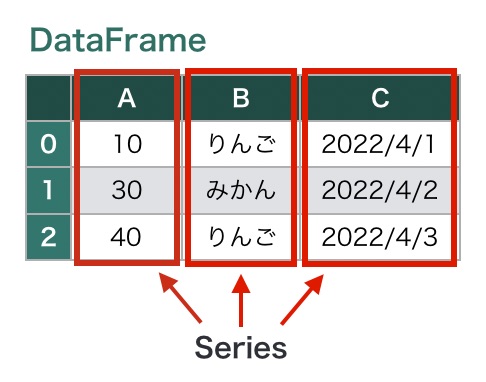
DataFrameクラスとSeriesクラスには、行や列を一括で処理するためのさまざまな機能が用意されています。そのため、Pythonのfor文を用いて1行ずつ処理するよりも、簡潔な記述で表形式データの操作ができます。
DataFrameの基本操作
まずは、pandasをインポートしましょう。pandasは慣例的にpd という略称が使われるため、ここでもpdと別名をつけてインポートします。
import pandas as pdさっそく、pandasの基本的なデータ構造であるDataFrameを作ってみましょう。
pd.DataFrame(リストのリスト)とすると、リストからDataFrameを作成できます。また、引数columnsを使って列名を指定できます。今回は名前・身長・体重のデータを扱うので、列名には[“Name”, “Height”, “Weight”]を指定しましょう。
# DataFrameの作成
df = pd.DataFrame(
[["佐藤", 172, 60], ["田中", 160, 50], ["鈴木", 165, 58]], # リスト
columns=["Name", "Height", "Weight"], # 列名のリスト
)作成したDataFrameの中身を確認してみましょう。Jupyter NotebookでDataFrame型の変数をセルの最後に書いて実行すると、見やすいスタイルで表示されます。
# 表示
df| Name | Height | Weight | |
|---|---|---|---|
| 0 | 佐藤 | 172 | 60 |
| 1 | 田中 | 160 | 50 |
| 2 | 鈴木 | 165 | 58 |
columns属性を使うと、DataFrameの列名一覧を確認できます。下記のコードを実行すると、作成時に引数columnsで指定した列名が表示されることがわかります。
df.columns
Index(['Name', 'Height', 'Weight'], dtype='object')
df[列名]のように書くと、列名を使ってDataFrameの各列の値にアクセスできます。ためしに列Nameを参照してみましょう。
df["Name"]
0 佐藤
1 田中
2 鈴木
Name: Name, dtype: objectDataFrameの1列分のデータは、Series型です。ためしに、先ほど参照した列Nameの型を確認すると、Series型であることがわかります。
type(df["Name"])
pandas.core.series.Series

コメント