

データのクリーニングで行うチェックには、次のようなものがあります。
- データのチェックの例:
- データの最大値・最小値を確認し、期待する範囲外の値がないか確認する
- 欠損値の有無を確認する
- データの種類を確認し、意図しない値や表記揺れがないか確認する
- データの分布を確認し、不自然な点がないか確認する
- データの重複を確認し、本来なら発生しないような不自然な重複がないか確認する
データの不自然な点に気付いたら、データ仕様が書かれたドキュメントを確認したり、データの入手元に問い合わせるなどして、なぜそのようなデータが発生しているのか背景の把握に努めます。その結果を踏まえた上で、どう対処するか決めます。
対処方法には次のようなものがあります。
- 対処方法の例:
- おかしなデータを、行または列ごと削除する
- おかしなデータを、他の値で置換する
データのクリーニングは地道な作業ですが、その後の分析結果の出来に関わる非常に重要な工程です。
データクリーニングの練習
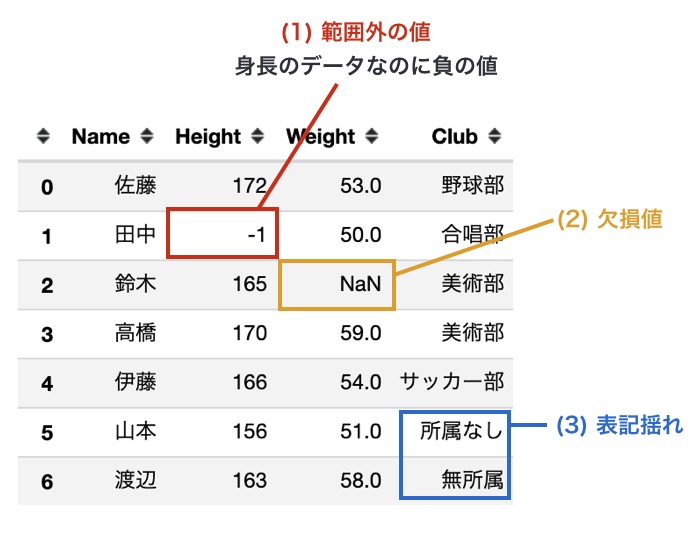
前回のクエストから引き続き、名前・身長・体重・部活動のデータを扱います。しかし今回扱うデータでは、次の3つの点でおかしなデータが混ざっています。
- (1) 範囲外の値: 身長のデータなのに、負の値になっている
- (2) 欠損値: 体重のデータが欠損している(
NaNは「データがないこと」を表す値) - (3) 表記揺れ: 部活動のデータに、同じような意味の値がある(
"無所属"と"所属なし")
範囲外のチェックと対応
import pandas as pd
# データの読み込み
df = pd.read_csv("dataset/physical_measurement_dirty.csv")
df| Name | Height | Weight | Club | |
|---|---|---|---|---|
| 0 | 佐藤 | 172 | 53.0 | 野球部 |
| 1 | 田中 | -1 | 50.0 | 合唱部 |
| 2 | 鈴木 | 165 | NaN | 美術部 |
| 3 | 高橋 | 170 | 59.0 | 美術部 |
| 4 | 伊藤 | 166 | 54.0 | サッカー部 |
| 5 | 山本 | 156 | 51.0 | 所属なし |
| 6 | 渡辺 | 163 | 58.0 | 無所属 |
desciribe()を使って基本統計量を表示し、何かおかしな点がないか確認してみましょう。 列Heightのmin(最小値)の項目が-1になっており、身長のデータとしてはおかしいことがわかります。
df.describe()| Height | Weight | |
|---|---|---|
| count | 7.000000 | 6.000000 |
| mean | 141.571429 | 54.166667 |
| std | 63.078938 | 3.656045 |
| min | -1.000000 | 50.000000 |
| 25% | 159.500000 | 51.500000 |
| 50% | 165.000000 | 53.500000 |
| 75% | 168.000000 | 57.000000 |
| max | 172.000000 | 59.000000 |
具体的にどの行がおかしいのか確認するために、「列Heightが0以下の行」を表示してみましょう。前回のクエスト「データを確認しよう」で学んだように、df[条件式]で行の絞り込みができます。実行すると、”田中”さんの行がおかしいことがわかります。
# 身長が0以下の行だけを選択
df[df["Height"] <= 0]Name | Height | Weight | Club | |
|---|---|---|---|---|
| 1 | 田中 | -1 | 50.0 | 合唱部 |
このようなおかしなデータが含まれる場合、実務での対処方法はいろいろありますが、今回は行自体を削除することにしましょう。
「列Heightが0以下の行を削除したい」ので、言い換えると「列Heightが0より大きい行だけを抽出したい」ことになります。そのためdf[条件式]で対応できます。
# 列Heightが0より大きい行だけを抽出
df_after = df[df["Height"] > 0]
df_after| Name | Height | Weight | Club | |
|---|---|---|---|---|
| 0 | 佐藤 | 172 | 53.0 | 野球部 |
| 2 | 鈴木 | 165 | NaN | 美術部 |
| 3 | 高橋 | 170 | 59.0 | 美術部 |
| 4 | 伊藤 | 166 | 54.0 | サッカー部 |
| 5 | 山本 | 156 | 51.0 | 所属なし |
| 6 | 渡辺 | 163 | 58.0 | 無所属 |
shapeを使って、削除前と削除後のDataFrameの行数を確認してみましょう。7行4列から6行4列に変わっており、1行減っていることがわかります。
print(df.shape) # 削除前のDataFrameの行数・列数
print(df_after.shape) # 削除後のDataFrameの行数・列数(7, 4)
(6, 4)次に、DataFrameの列Heightの最小値を、削除前と削除後で比較しましょう。 df[列名].min() で、指定した列の最小値を確認できます。次のコードを実行すると、削除前は列Heightの最小値が-1だったのに対し、削除後は156になっており、不自然な値が取り除かれていることがわかります。
#ここでprintがなくてもOK
print(df["Height"].min()) # 削除前の身長の最小値
print(df_after["Height"].min()) # 削除後の身長の最小値-1 156

コメント