

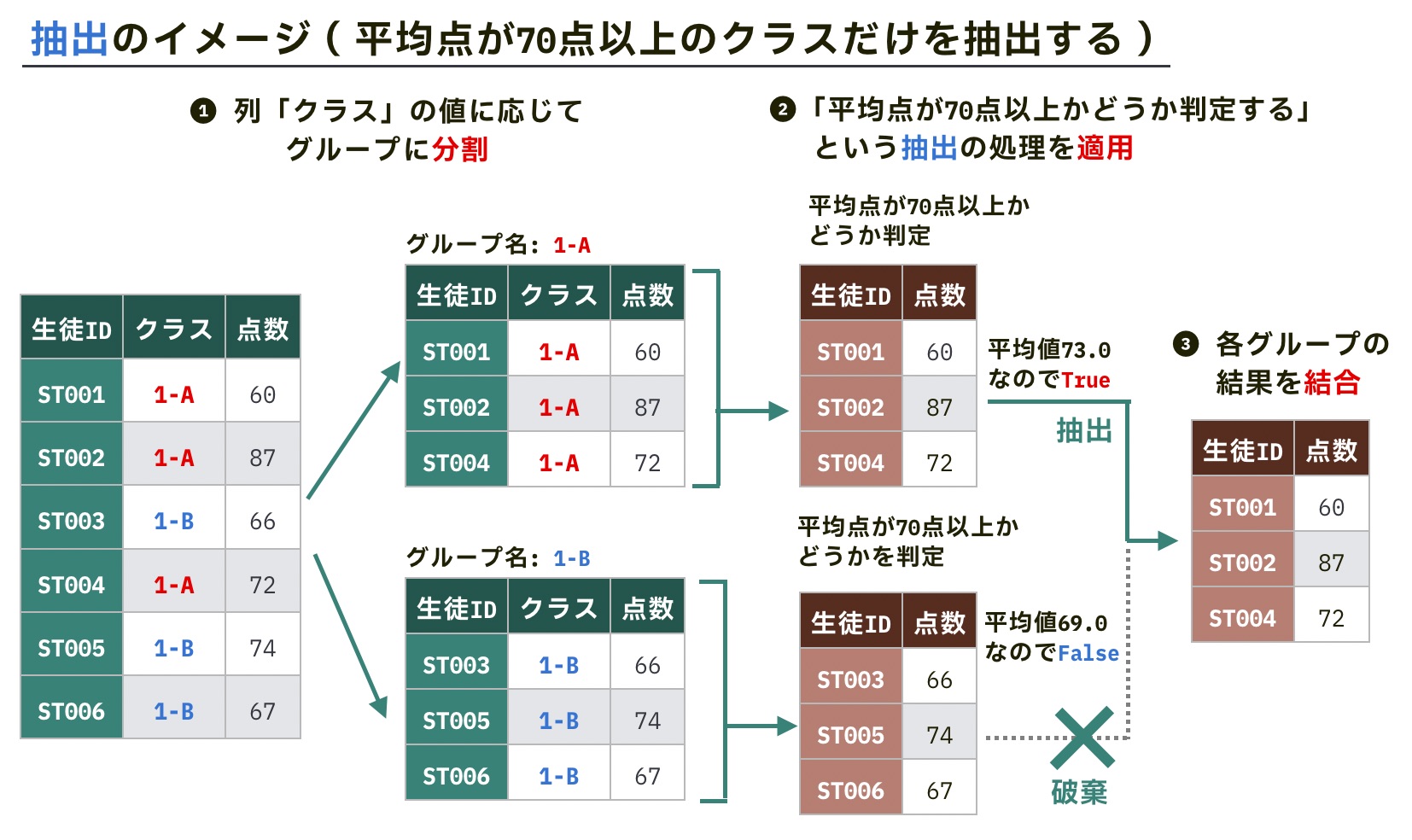
抽出(filter)は、指定した条件に合致するグループのデータだけを取得する ような処理です。たとえば次のようなケースです。
- 複数クラスの試験結果のデータから、「平均点が70点以上のクラス」のデータを抽出する
- 複数ユーザーの購入履歴ログから、「購入回数が5回以上のユーザー」のデータを抽出する
- 複数支店の月次売上データから、「月の平均売上が50万円未満の支店」のデータを抽出する
このような場合は、filter()が便利です。
DataFrameGroupByのfilter()
DataFrameGroupByのfilter()は、次のように 各グループを抽出するかどうかブール値を返す関数 を指定して使います。
# 指定した列名でグループ化する
grouped = df.groupby(列名)
# 条件に合致するグループだけを抽出する
grouped.filter(ブール値を返す関数)関数は、「引数で各グループのDataFrameを受け取り、戻り値でブール値(True/False)を返す」 ように定義します。Trueを返したグループだけが抽出されます。
具体的な例を見てみましょう。次のような試験結果と学習時間のデータについて考えます。
生徒ID | クラス | 点数 | 学習時間(分) |
|---|---|---|---|
| ST001 | 1-A | 60 | 232 |
| ST002 | 1-A | 87 | 345 |
| ST003 | 1-B | 66 | 180 |
| ST004 | 1-A | 72 | 22 |
| ST005 | 1-B | 74 | 120 |
| ST006 | 1-B | 58 | 215 |
このデータから、「列点数の平均点が70点以上のクラス」 のデータだけを抽出したいとします。クラス1-Aの平均点が73点、クラス1-Bの平均点が66点なので、「1-Aのデータだけが抽出される」のが期待する結果です。
まず次のように、各グループのDataFrameを受け取り、「列点数の平均点が70点以上かどうか」を判定する関数を作成します。引数g_dfには、各グループのDataFrameが渡されます。
def is_70points_or_more(g_df):
# 平均点が70点以上かどうかを判定する関数
# 引数g_dfには各グループのDataFrameが渡される
return g_df["点数"].mean() >= 70次のようにfilter()を使って上記の関数を適用します。
# 列「クラス」でグループ化
grouped = df.groupby("クラス")
# 抽出関数を指定
grouped.filter(is_70points_or_more)生徒ID | クラス | 点数 | 学習時間(分) |
|---|---|---|---|
| ST001 | 1-A | 60 | 232 |
| ST002 | 1-A | 87 | 345 |
| ST004 | 1-A | 72 | 22 |
期待通り、平均点が73点であるクラス1-AのDataFrameは抽出され、平均点が66点であるクラス1-BのDataFrameは抽出されていないことがわかります。
SeriesGroupByのfilter()
SeriesGroupByのfilter()では、引数として各グループのSeriesを受け取り、戻り値でブール値を返す関数を記述します。DataFrameGroupByのfilter()とは引数の型が違う点に注意しましょう。
先ほどの「平均点が70点以上のクラスだけを抽出する処理」をSeriesGroupByを使って置き換えると、次のようになります。
def is_70points_or_more(sr):
# 平均点が70点以上かどうかを判定する関数
# 引数srには各グループのSeriesが渡される
return sr.mean() >= 70
# 抽出関数を指定
grouped["点数"].filter(is_70points_or_more)実行結果
生徒ID
ST001 60
ST002 87
ST004 72
Name: 点数, dtype: int64期待通り、1-Aのデータだけが抽出されていることがわかります。
演習
まずは、今回使うデータを読み込みましょう。1行あたり1生徒のデータで、所属するクラス・試験の点数、学習時間(分)を表す列があります。
import pandas as pd
# 試験結果のデータの読み込み
df = pd.read_csv("dataset/score_study_time_club.csv", index_col="生徒ID")
# 先頭5行を確認
df.head()
Out[1]:
| クラス | 点数 | 学習時間(分) | 部活動 | |
|---|---|---|---|---|
| 生徒ID | ||||
| ST001 | 1-A | 48.0 | 226 | 合唱部 |
| ST002 | 1-A | 0.0 | 24 | 科学部 |
| ST003 | 1-B | 80.0 | 271 | 科学部 |
| ST004 | 1-A | NaN | 45 | 合唱部 |
| ST005 | 1-A | 68.0 | 271 | 美術部 |
今回はクラスごとに平均点を計算してデータを抽出するので、groupby()を使ってクラスごとにグループ化します。
# 列「クラス」でグループ化
grouped = df.groupby("クラス")
期待する結果を確認するために、先に各クラスの平均点を確認しましょう。 1-Aの平均点が66.222222点、1-Bの平均点が70.500000点です。今回は 平均点が70点未満のデータだけを抽出したい ので、「1-Aのデータだけが抽出される」のが期待する結果となります。
# 各グループの平均値を確認 grouped.mean()
| 点数 | 学習時間(分) | |
|---|---|---|
| クラス | ||
| 1-A | 66.222222 | 245.1 |
| 1-B | 70.500000 | 244.9 |
filter()を使うと、指定した関数に基づいて条件に合致するグループだけを抽出できます。
まずは、グループが抽出対象かどうかを判定するための関数 を定義しましょう。各グループのDataFrameを引数で受け取り、抽出対象である場合はTrue、そうでない場合はFalseを返す関数を定義します。今回の抽出条件は「列点数の平均点が70点未満」なので、次のように書きます。
def is_low_mean(g_df):
# 点数の平均が70未満かどうかを判定する
# 引数g_dfには各グループのDataFrameが渡される
return g_df["点数"].mean() < 70
→ここをg_gf.mean()<70とすると、他の列にも適応されてしまう。
定義した関数をfilter()で指定して実行しましょう。実行すると、1-Aのデータだけが抽出されることがわかります。
# 列「点数」の平均が70未満のグループのデータだけを抽出する low_mean_df = grouped.filter(is_low_mean) low_mean_df
| クラス | 点数 | 学習時間(分) | 部活動 | |
|---|---|---|---|---|
| 生徒ID | ||||
| ST001 | 1-A | 48.0 | 226 | 合唱部 |
| ST002 | 1-A | 0.0 | 24 | 科学部 |
| ST004 | 1-A | NaN | 45 | 合唱部 |
| ST005 | 1-A | 68.0 | 271 | 美術部 |
| ST007 | 1-A | 49.0 | 236 | ラグビー部 |
| ST011 | 1-A | 98.0 | 381 | 科学部 |
| ST012 | 1-A | 84.0 | 286 | ラグビー部 |
| ST017 | 1-A | 81.0 | 355 | 科学部 |
| ST019 | 1-A | 78.0 | 326 | サッカー部 |
| ST020 | 1-A | 90.0 | 301 | サッカー部 |
filter()はSeriesGroupByでも使えます。その場合、適用する関数は 各グループのSeries を引数で受け取るように定義します。
def is_low_mean(sr):
# 平均が70未満かどうかを判定する関数
# 引数srには各グループのSeriesが渡される
return sr.mean() < 70
low_mean_sr = grouped["点数"].filter(is_low_mean)
low_mean_sr
生徒ID ST001 48.0 ST002 0.0 ST004 NaN ST005 68.0 ST007 49.0 ST011 98.0 ST012 84.0 ST017 81.0 ST019 78.0 ST020 90.0 Name: 点数, dtype: float64

コメント