

1.関数は列方向に作用する
df.max()
→列ごとの最大値がリターンする。2.関数を組み合わせると、列ごとに関数の計算が行われる。
def calc_range(column):
# 最高点と最低点の差を計算する関数
# 引数columnには各列のSeriesが渡される
diff = column.max() - column.min()
return diff# 行方向の処理(列ごとに適用される)
result_sr = df.apply(calc_range, axis=0)
result_sr国語 32
数学 21
dtype: int64
3. axis=1を入れると初めて、行方向の計算になる
4.個別の数値に関わりたい場合
def count(row):
num=0
for time in ["国語","数学","理科","社会"]:
if row[time]>=30:
num=num+1
return numこのようにforで一つひとつを取り上げて、数字を判定するには、このように書く。
解説 Seriesに対して一つ一つの値に対して数字をチェックするのは、
list1 = [1, 2, 3]
index1 = ["Row1", "Row2", "Row3"]
ser1 = pd.Series(data = list1, index = index1)
ser1[“Row2”]2となる。
つまり、df.apply(関数)となると、
関数=pd.Series()の形になる。
このため、個別の値は、関数[“Index”]となる。
関数は、Seriesを直接代入することになるため、Seriesに対して何をするべきか書く必要がある。
演習解説
「行ごとに30分以上勉強した科目の数を計算したい」ので、「行ごとに複数の列(列国語、数学、理科、社会)の値を見て30分以上の科目の数を計算したい」ことになります。
このように複数列または複数行の値を使うデータ処理では、DataFrameのapply()を使います。
# 指定した処理の方向に応じて、行または列に関数を適用
df.apply(関数, axis=処理の方向)今回は行ごとに科目の数を数えたい、つまり列方向の処理となるので、引数axisに1を指定します。
df.apply(30分以上勉強した科目数を数える関数, axis=1)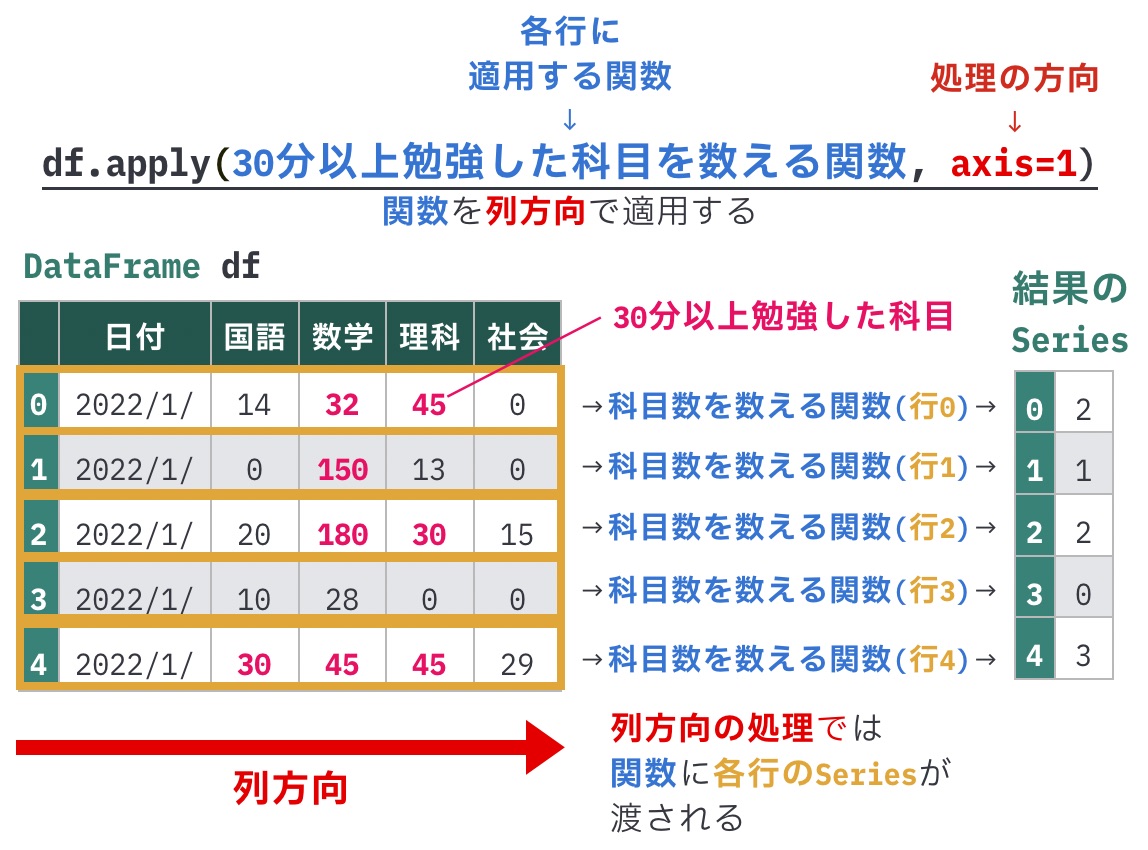
「30分以上勉強した科目数を数える関数」では、第1引数で各行に相当するSeriesを受け取って、戻り値で計算結果を返すようにします。
模範解答では関数名はcount_studied_subjectにしていますが、名前は何でも構いません。
def count_studied_subject(row):
# 30分以上勉強した科目数を数える
count = 0
# すべての科目の列について、30分以上かどうかチェックする
for column in ["国語", "数学", "理科", "社会"]:
if row[column] >= 30:
# 30分以上勉強していたらカウントする
count += 1
return countrow[列名]で指定した列の値を参照できるので、for文の中で各列ごとに30分以上かどうか判定してカウントしています。
列方向の処理なので、apply()実行時には引数axisで1を指定します。また、apply()を使っただけでは元のdfは更新されないので、実行結果のSeriesを新しい列として追加します。
# 「30分以上勉強した科目数を数える関数」を列方向で適用する
df["30分以上勉強した科目数"] = df.apply(count_studied_subject, axis=1)
コメント