

一般的に表は2次元のデータです。例えば、以下のようにリストを要素に持つリストは、2次元のデータとみなせます。
[[1, 2], [3, 4]]pandasでは、2次元の表はDataFrameというデータ構造で扱います。下記のように、リストのリストを使ってDataFrameを作成してみましょう。
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]])
df| 0 | 1 | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
dfは、DataFrame型のオブジェクトです。Jupyterのセルにdfと書いて実行すると、上表のように出力されます。dfは、 [[1, 2], [3, 4]] のデータからできていますが、左端と上端に 0, 1 という表示があります。左端の0, 1はインデックスで、各行についた名前です。上端の0, 1は列名(Column)一覧で、各列についた名前です。インデックスと列名一覧はpandas.index型、あるいはそのサブクラス(Int64Index型など)でできています。
このように、DataFrameはインデックス、列名一覧、データの3つの要素で構成されます。
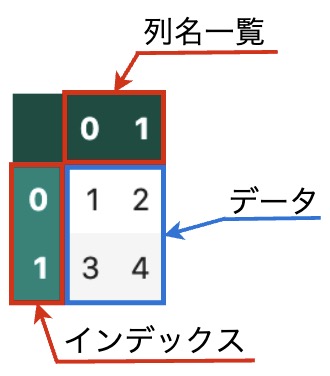
- データを処理するために、DataFrameは、行方向にインデックス、列方向に列名一覧という部品を持っています。
- Jupyterで
dfと書いて実行すると、左端にインデックスが、上端に列名一覧が表示されます。
Dfの構成要素の取り出し
DataFrame型の変数dfの3つの部分は、それぞれ以下のように取得できます。
df.index:インデックスdf.columns:列名一覧df.to_numpy():データ
また、下記のようにすると、DataFrameの作成時に、インデックスと列名一覧を引数indexと引数columnsで指定できます。
下記では、[10, 20]をインデックスに、["Name", "Age"]を列名一覧に指定しています。
import pandas as pd
df = pd.DataFrame(
[["Alice", 17], ["Bob", 24]],
index=[10, 20],
columns=["Name", "Age"],
)
df| Name | Age | |
|---|---|---|
| 10 | Alice | 17 |
| 20 | Bob | 24 |
dfのインデックスは、df.indexで取得します。実行結果に表示されるInt64Indexはpandas.Index型のサブクラスです。
df_index = df.index
df_indexInt64Index([10, 20], dtype='int64')
int64は符号あり64ビット整数型という事。
dfの列名一覧は、df.columnsで取得します。実行結果に表示されるIndexは、pandas.Index型を意味します。
df_columns = df.columns
df_columnsIndex(['Name', 'Age'], dtype='object')
dfのデータは、df.to_numpy()で取得します。結果は2次元のデータ構造です。
df_data = df.to_numpy()
df_dataarray([['Alice', 17],
['Bob', 24]], dtype=object)
object型は特殊なデータ型で、Pythonオブジェクトへのポインターを格納する。各要素のデータはそれぞれ別の型を持つ場合がある。strが文字列。strとは限らない。
インデックスと列名一覧の変更
indexとcolumnsを指定せずにDataFrameを作成します。
import pandas as pd
df = pd.DataFrame([["Alice", 17], ["Bob", 24]])
df| 0 | 1 | |
|---|---|---|
| 0 | Alice | 17 |
| 1 | Bob | 24 |
df.indexを指定します。インデックスが変わることを確認してください。
df.index = [10, 20] #df.index=という形にする
df| 0 | 1 | |
|---|---|---|
| 10 | Alice | 17 |
| 20 | Bob | 24 |
df.columnsを指定します。列名一覧が変わることを確認してください。
df.columns = ["Name", "Age"] このイコールが必要
df| Name | Age | |
|---|---|---|
| 10 | Alice | 17 |
| 20 | Bob | 24 |
データの取得と変更
特定の行、特定の列、その交差部分は、以下のように取得と変更ができます。
- 特定の行は、
df.loc[行名]で指定できます。→この行が基本形 - 特定の列は、
df.loc[:, 列名]で指定できます(:は全ての行を意味します)。
つまり、df.loc[すべての行の、この列]という事。
簡単にするためには、df[列名]でOK - 特定の行、特定の列は、
df.loc[行名, 列名]で指定できます。
特定の列に関しては、df[列名]やdf.列名といった記述方法も可能です。通常は、こちらの方が記述しやすいでしょう。ただし、df.loc[:, 列名]で列が取得できることも覚えてください。これを覚えることで、後々、複雑な使い方が必要なときに基本に立ち返って考えられるようになります。
import pandas as pd
df = pd.DataFrame(
[["Alice", 17], ["Bob", 24]],
index=[10, 20],
columns=["Name", "Age"],
)
df| Name | Age | |
|---|---|---|
| 10 | Alice | 17 |
| 20 | Bob | 24 |
行名が10の行を取得します。
df.loc[10]Name Alice Age 17 Name: 10, dtype: object
行名が10の行を変更し、確認します。
df.loc[10] = ["Carol", 18]
df.loc[10]Name Carol
Age 18
Name: 10, dtype: object列名がAgeの列を取得します。
# 列の取得方法その1
df.loc[:, "Age"]10 18 20 24 Name: Age, dtype: int64
同様に、列名がAgeの列を取得します。こちらの方法が簡単です。
# 列の取得方法その2
df["Age"]10 18 20 24 Name: Age, dtype: int64
同様に、列名がAgeの列を取得します。こちらの方法でも問題ありません。
# 列の取得方法その3
df.Age10 18 20 24 Name: Age, dtype: int64
注意:この方法は間違えやすいので、使わない。
列名がAgeの列を変更し、確認します。
# 列の変更方法その1
df.loc[:, "Age"] = [19, 25]
df.loc[:, "Age"]10 19 20 25 Name: Age, dtype: int64
同様に、列名がAgeの列を変更し、確認します。こちらの方法が簡単です。
# 列の変更方法その2
df["Age"] = [19, 25]
df["Age"]10 19 20 25 Name: Age, dtype: int64
同様に、列名がAgeの列を変更し、確認します。こちらの方法でも問題ありません。
# 列の変更方法その3
df.Age = [19, 25]
df.Age10 19 20 25 Name: Age, dtype: int64
行名が20で、列名がAgeの列を取得します。
df.loc[20, "Age"]25
行名が20で、列名がAgeの列を変更し、確認します。
df.loc[20, "Age"] = 26
df.loc[20, "Age"]26
複数列や複数行に渡って範囲を取得・変更する場合
df.loc[行名, 列名のリスト]df.loc[行名のリスト, 列名]→つまり、df.loc[[”A”,”B”], ”age”]などになる。df.loc[行名のリスト, 列名のリスト]
行名では1つの行を特定しますが、行名のリストでは複数行を特定します。
同様に、列名のリストは複数列を特定します。
df.loc[:, 列名のリスト]df[列名のリスト]
import pandas as pd
df = pd.DataFrame(
[["Alice", 17, "A"], ["Bob", 24, "B"], ["Carol", 29, "C"]],
index=[10, 20, 30],
columns=["Name", "Age", "Team"],
)
df| Name | Age | Team | |
|---|---|---|---|
| 10 | Alice | 17 | A |
| 20 | Bob | 24 | B |
| 30 | Carol | 29 | C |
df.loc[行名, 列名のリスト]の形式の取得方法を確認しましょう。 行名が10で、列名がNameとAgeのデータを取得します。
df.loc[10, ["Name", "Age"]]Name Alice Age 17 Name: 10, dtype: object
続いて、変更について見てみます。 行名が10で、列名がNameとAgeのデータを変更し、確認します。
df.loc[10, ["Name", "Age"]] = ["Amanda", 18]
df.loc[10, ["Name", "Age"]]Name Amanda Age 18 Name: 10, dtype: object
次にdf.loc[行名のリスト, 列名]の形式の取得方法を確認しましょう。 行名が10と20で、列名がAgeのデータを取得します。
df.loc[[10, 20], "Age"]複数を選択する場合には、df.loc[[A,B]]となる
10 18
20 24
Name: Age, dtype: int64行名が10と20で、列名がNameとAgeのデータを変更し、確認します。
df.loc[[10, 20], "Age"] = [21, 27]
df.loc[[10, 20], "Age"]10 21 20 27 Name: Age, dtype: int64
さらにdf.loc[行名のリスト, 列名のリスト]の形式の取得方法を確認しましょう。 行名が10と20で、列名がNameとAgeのデータを取得します。
df.loc[[10, 20], ["Name", "Age"]]| Name | Age | |
|---|---|---|
| 10 | Amanda | 21 |
| 20 | Bob | 27 |
行名が10と20で、列名がNameとAgeのデータを変更し、確認します。
df.loc[[10, 20], ["Name", "Age"]] = [["Ada", 19], ["Ben", 28]]
df.loc[[10, 20], ["Name", "Age"]]| Name | Age | |
|---|---|---|
| 10 | Ada | 19 |
| 20 | Ben | 28 |
locを使わないで複数の列を取得する場合は、df[列名のリスト]のように書きます。次のコードをでは、列Nameと列Teamのデータを取得しています。
df[["Name", "Team"]]| Name | Team | |
|---|---|---|
| 10 | Ada | A |
| 20 | Ben | B |
| 30 | Carol | C |
同様にlocを使わずに、列名がNameとTeamのデータを変更し、その結果を確認します。
df[["Name", "Team"]] = [["Dana", "D"], ["Eve", "E"], ["Grace", "G"]]
df[["Name", "Team"]]| Name | Team | |
|---|---|---|
| 10 | Dana | D |
| 20 | Eve | E |
| 30 | Grace | G |

コメント