

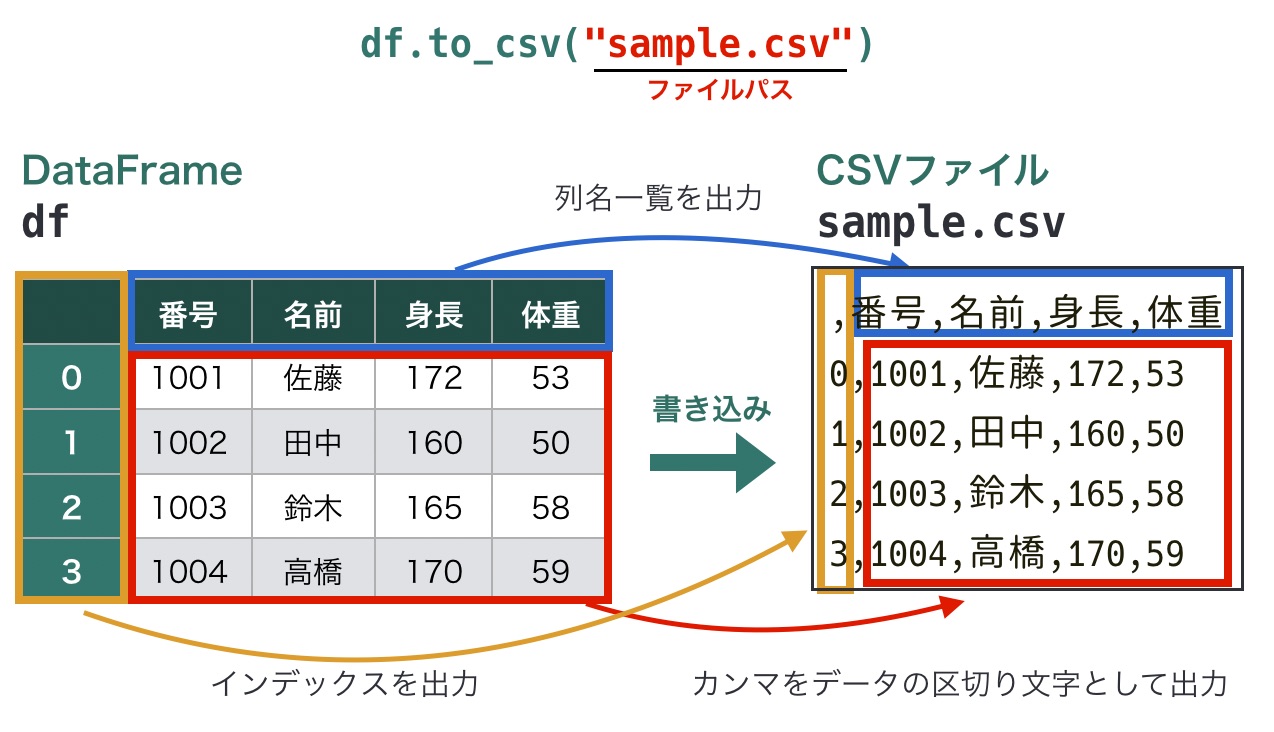
DataFrameの中身をCSVファイルに書き込む際は、to_csv()メソッドを使います。次のように、第1引数に書き込み先のファイルのパスを指定します。
df.to_csv(ファイルパス)read_csv()同様、to_csv()にもさまざまなオプションがありますが、デフォルトでは次のように動作します。
- インデックス: 出力する
- 列名一覧: 出力する
- 区切り文字: カンマ区切り(
,)
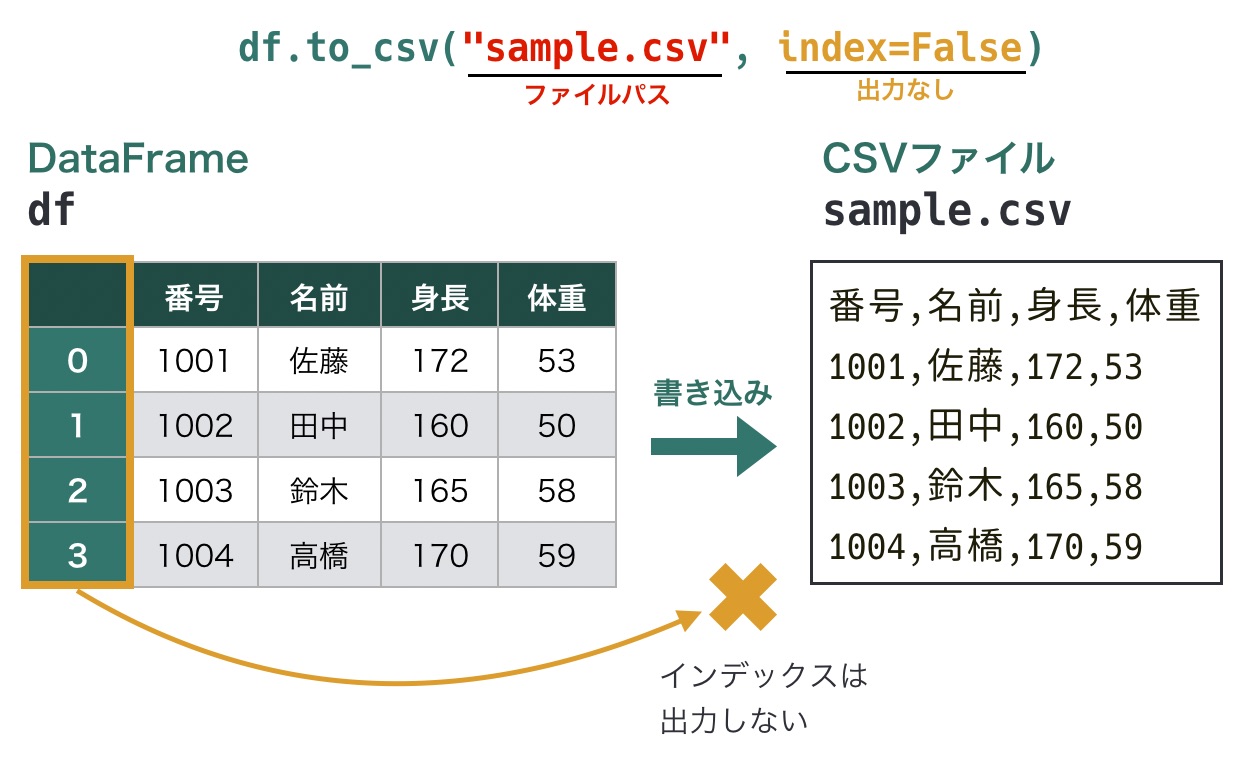
read_csv()同様、これらの動作は引数によって変更できます。たとえば、インデックスを出力しない場合は、引数indexでFalseを指定します。
これをしないと、無駄なindex列がcsvファイルに出現する。
to_csv()で用意されているオプションは、公式のAPIリファレンスで確認できます。
演習
import pandas as pd
# DataFrameの作成
df = pd.DataFrame(
[
["1001", "佐藤", 172, 60],
["1002", "田中", 160, 50],
["1003", "鈴木", 165, 58],
["1004", "高橋", 170, 59],
],
columns=["StudentID", "Name", "Height", "Weight"],
)
df| StudentID | Name | Height | Weight | |
|---|---|---|---|---|
| 0 | 1001 | 佐藤 | 172 | 60 |
| 1 | 1002 | 田中 | 160 | 50 |
| 2 | 1003 | 鈴木 | 165 | 58 |
| 3 | 1004 | 高橋 | 170 | 59 |
さっそく、このDataFrameをファイルに出力してみましょう。pandasでCSVファイルに保存するには、to_csv()を使います。to_csv()にはいろいろなオプションがありますが、まずはデフォルトの動作を確認してみましょう。
# CSVの書き込み(デフォルト)
df.to_csv("out_default.csv")catコマンドを使って、保存したファイルの中身を確認しましょう。次の3点が確認できます。
- インデックスが出力されていること
- 列名一覧が出力されていること
- 区切り文字がカンマ(
,)であること
!cat out_default.csv,StudentID,Name,Height,Weight 0,1001,佐藤,172,60 1,1002,田中,160,50 2,1003,鈴木,165,58 3,1004,高橋,170,59
to_csv()にはいろいろなオプションがあります。たとえば引数indexにFalseを指定すると、インデックスを除外して保存できます。
インデックスの除外
# インデックスを除外して書き込み
df.to_csv("out_without_index.csv", index=False)catコマンドを使って、保存したファイルの中身を確認しましょう。デフォルトの時とは違い、インデックスが出力されていないことが確認できます。
StudentID,Name,Height,Weight 1001,佐藤,172,60 1002,田中,160,50 1003,鈴木,165,58 1004,高橋,170,59
ヘッダーの除外
to_csv()は、デフォルトでは列名一覧を含めて出力しますが、引数headerでFalseを指定することで列名一覧を除外して出力できます。
# 列名一覧を除外して書き込み
df.to_csv(ファイルパス, header=False)
区切り文字の指定
to_csv()ファイルは、デフォルトではカンマ(,)でデータを区切ってCSVファイルを出力します。
カンマ以外の区切り文字を使いたい場合は、引数sepで指定できます。また、ファイルパスでcsv以外の拡張子(txtやtsvなど)を指定することも可能です。
# 区切り文字を指定して書き込み
df.to_csv(ファイルパス, sep=区切り文字)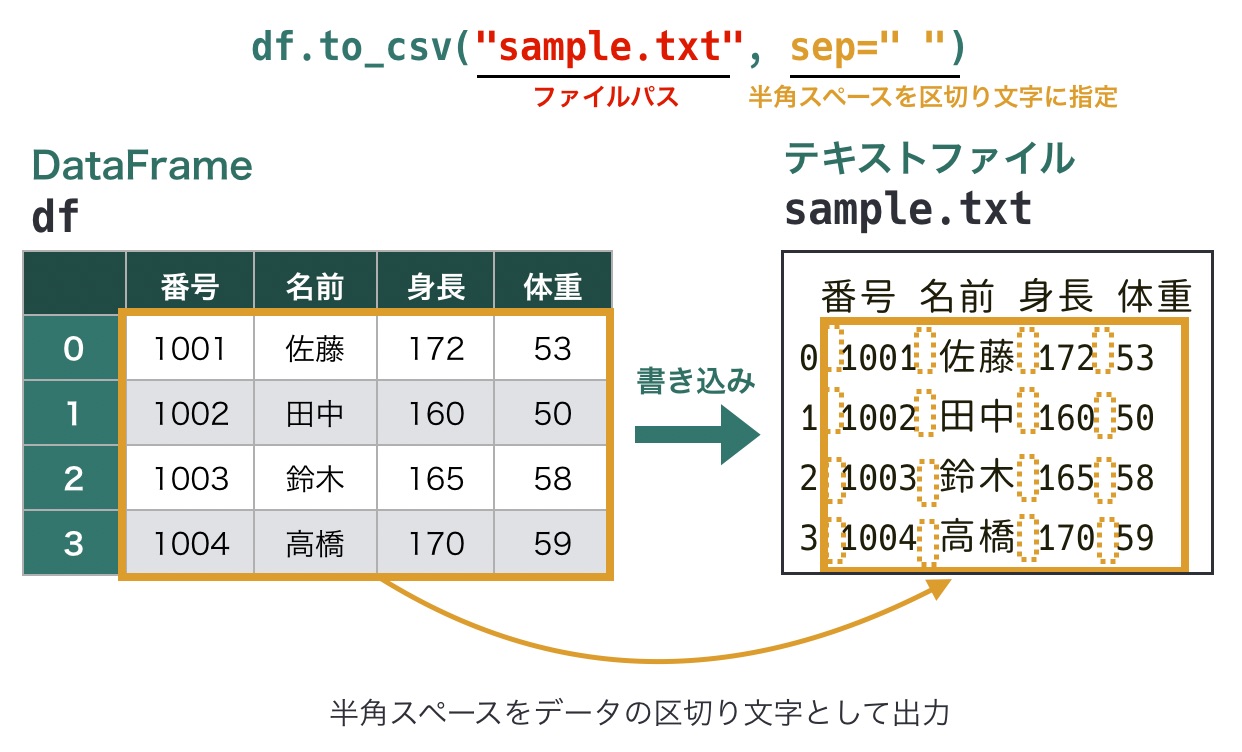
# 半角スペース区切りで書き込み
df.to_csv("out_space.txt", sep=" ")StudentID Name Height Weight 0 1001 佐藤 172 60 1 1002 田中 160 50 2 1003 鈴木 165 58 3 1004 高橋 170 59
エクセルでの保存
DataFrameの中身をExcelに書き込みたいときはto_excel()メソッドを使います。
# Excelファイルに書き込み
df.to_excel(Excelファイルのパス, sheet_name=シート名)to_csv()同様、to_excel()でも引数index, headerなどで保存形式をカスタマイズできます。また、出力先のシートは引数sheet_nameで指定します。
エンコーディングの指定
to_csv()では、デフォルトではUTF-8でファイルを保存します。
UTF-8以外の文字エンコーディングで保存する場合は、引数encodingを使います。
# 文字エンコーディングを指定して書き込み
df.to_csv(ファイルパス, encoding=文字エンコーディング)read_csv()の引数encoding同様、Pythonに標準で用意されている文字列が使えます。
たとえば、次のようなものです。
| エンコーディング | 指定する文字列 |
|---|---|
| UTF-8 | "utf-8" |
| Shift_JIS | "shift_jis" |
| ASCII | "ascii" |
import pandas as pd
# DataFrameの作成
df = pd.DataFrame(
[
["1001", "佐藤", 172, 60],
["1002", "田中", 160, 50],
["1003", "鈴木", 165, 58],
["1004", "高橋", 170, 59],
],
columns=["StudentID", "Name", "Height", "Weight"],
)
df| StudentID | Name | Height | Weight | |
|---|---|---|---|---|
| 0 | 1001 | 佐藤 | 172 | 60 |
| 1 | 1002 | 田中 | 160 | 50 |
| 2 | 1003 | 鈴木 | 165 | 58 |
| 3 | 1004 | 高橋 | 170 | 59 |
出力時のエンコーディングは、引数encodingで指定できます。Shift_JISで保存する場合は、”shift_jis”を指定します。
# Shift_JISで書き込み
df.to_csv("out_sjis.csv", encoding="shift_jis")保存したファイルを読み込んで確認してみましょう。出力時と同じエンコーディング(”shift_jis”)を指定すると、文字化けもエラーも起きずに読み込めることがわかります。なおインデックスを含めて出力したため、引数index_colで最初の列(列0)を指定して読み込んでいます。
# Shift_JISで読み込み
df_out = pd.read_csv("out_sjis.csv", encoding="shift_jis", index_col=0)
df_out| StudentID | Name | Height | Weight | |
|---|---|---|---|---|
| 0 | 1001 | 佐藤 | 172 | 60 |
| 1 | 1002 | 田中 | 160 | 50 |
| 2 | 1003 | 鈴木 | 165 | 58 |
| 3 | 1004 | 高橋 | 170 | 59 |

コメント