

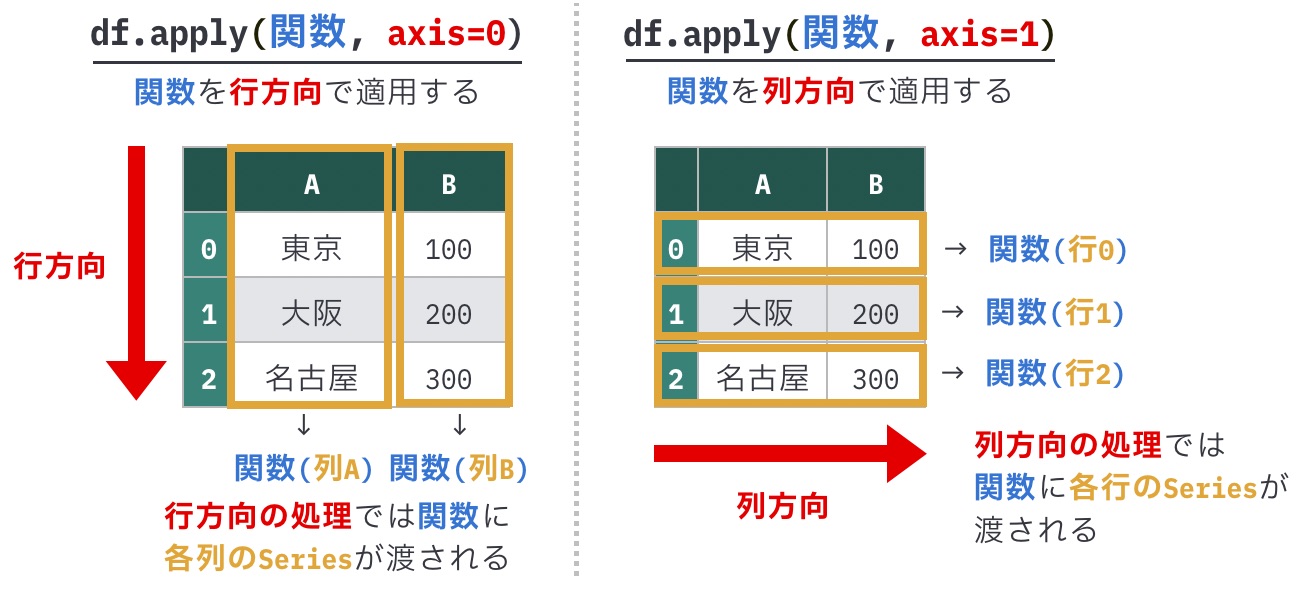
行方向の処理を行いたいときは、引数axisに0を指定します。なお引数axisのデフォルト値は0なので、未指定の場合も自動的に行方向の処理になります。
以下に、行方向の処理と列方向の処理の違いを再掲します。
0: 行方向の処理。関数の第1引数には列のSeriesが渡される(今回の問題で説明)1: 列方向の処理。関数の第1引数には行のSeriesが渡される(前の問題で説明)
行方向(0)の処理では列ごとに、列方向(1)の処理では行ごとに関数が適用される点に注意してください。
具体的な例を見てみましょう。次のような成績のテストで、各科目ごとに「最高点と最低点の差」を求めたいとします。
ユーザーID | 国語 | 数学 |
|---|---|---|
| user1 | 90 | 100 |
| user2 | 92 | 90 |
| user3 | 60 | 90 |
| user4 | 78 | 79 |
国語は最高点が92、最低点が60なので、結果は32になります。
数学は最高点が100、最低点が79なので、結果は21になります。
列ごとにすべての行の値を見る必要があるので、この処理は「列ごとに複数の行の値を使う処理」つまり行方向の処理となります。
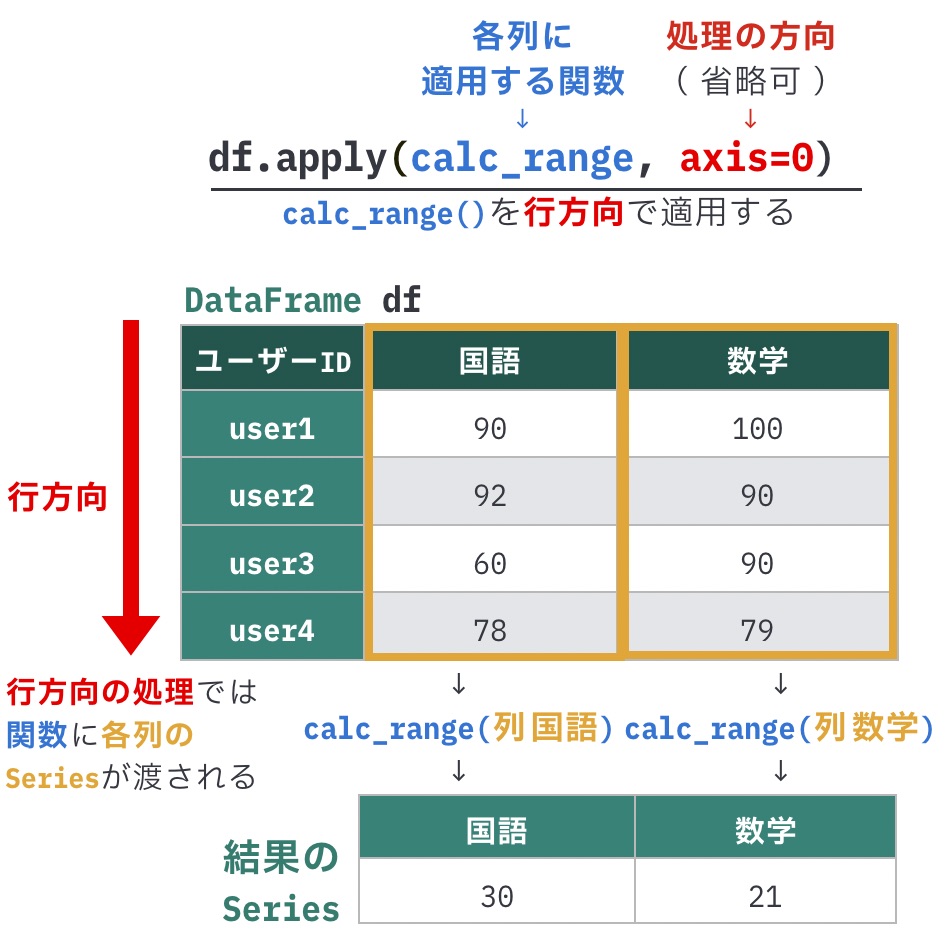
最高点と最低点の差を求める関数を書くと、次のようになります。第1引数であるcolumnには、各列に相当するSeriesが渡されます。
def calc_range(column):
# 最高点と最低点の差を計算する関数
# 引数columnには各列のSeriesが渡される
diff = column.max() - column.min()
return diff
# 関数を列ごとに適用(=行方向の処理)
df国語 32
数学 21
dtype: int64演習
import pandas as pd
# テストの成績を読み込み
df = pd.read_csv("dataset/score_apply.csv", index_col="ユーザーID")
df| 国語 | 数学 | |
|---|---|---|
| ユーザーID | ||
| user1 | 90 | 100 |
| user2 | 92 | 90 |
| user3 | 60 | 90 |
| user4 | 78 | 79 |
引数axisの挙動の確認
引数axisに0を指定した場合と1を指定した場合の挙動の違いを確認しましょう。
apply()の引数axisに0を指定すると、行方向の処理になり、引数には各列に相当するSeriesが渡されます。 受け取った引数の値を表示するだけのシンプルな関数を使って確認してみましょう。
最初に列国語、次に列数学の中身が表示され、列ごとに処理が適用されていることがわかります。
def print_series(sr):
print(sr)
print("========")
# 行方向の処理(列ごとに処理が適用される)
df.apply(print_series, axis=0)ユーザーID user1 90 user2 92 user3 60 user4 78 Name: 国語, dtype: int64 ======== ユーザーID user1 100 user2 90 user3 90 user4 79 Name: 数学, dtype: int64 ========
国語 None 数学 None dtype: object
次に、前問でやったように引数axis=1を指定してみましょう。
今度は、user1、user2……と各行に相当するSeriesが出力され、行ごとに処理が適用されていることがわかります。
# 列方向の処理(行ごとに処理が適用される)
df.apply(print_series, axis=1)国語 90 数学 100 Name: user1, dtype: int64 ======== 国語 92 数学 90 Name: user2, dtype: int64 ======== 国語 60 数学 90 Name: user3, dtype: int64 ======== 国語 78 数学 79 Name: user4, dtype: int64
ユーザーID
user1 None
user2 None
user3 None
user4 None
dtype: object各科目の最高点と最低点の差
次に、より実践的な例として、apply()を使って各科目の最高点と最低点との差を求めてみましょう。
各科目ごとに処理を行いたい、つまり列ごとに処理を行いたいため、列のSeriesを受け取ることを想定した関数を定義します。
def calc_range(column):
# 最高点と最低点の差を計算する関数
# 引数columnには各列のSeriesが渡される
diff = column.max() - column.min()
return diff作成した関数をapply()を使って適用し、変数result_srに格納しましょう。
列ごとに適用する場合行方向の処理になるため、引数axisには0を指定します。
# 行方向の処理(列ごとに適用される)
result_sr = df.apply(calc_range, axis=0)
result_sr国語 32
数学 21
dtype: int64なお引数axisのデフォルト値は0のため、次のように省略しても同じ結果になります。
# axisを省略した場合
df.apply(calc_range)国語 32
数学 21
dtype: int64
コメント