

複数の列や複数の行の値を使いたい場合はどうすればよいでしょうか。たとえば、次のようなケースです。
- 列
支払い総額と列年齢の値に応じて、ユーザーをカテゴリー分けしたい - 列
商品の金額と列購入者数に応じて、商品をカテゴリー分けしたい
このような場合、DataFrameのapply()を使うことで実現できます。
# DataFrameのapply
# 指定した処理の方向に応じて、行または列に関数を適用
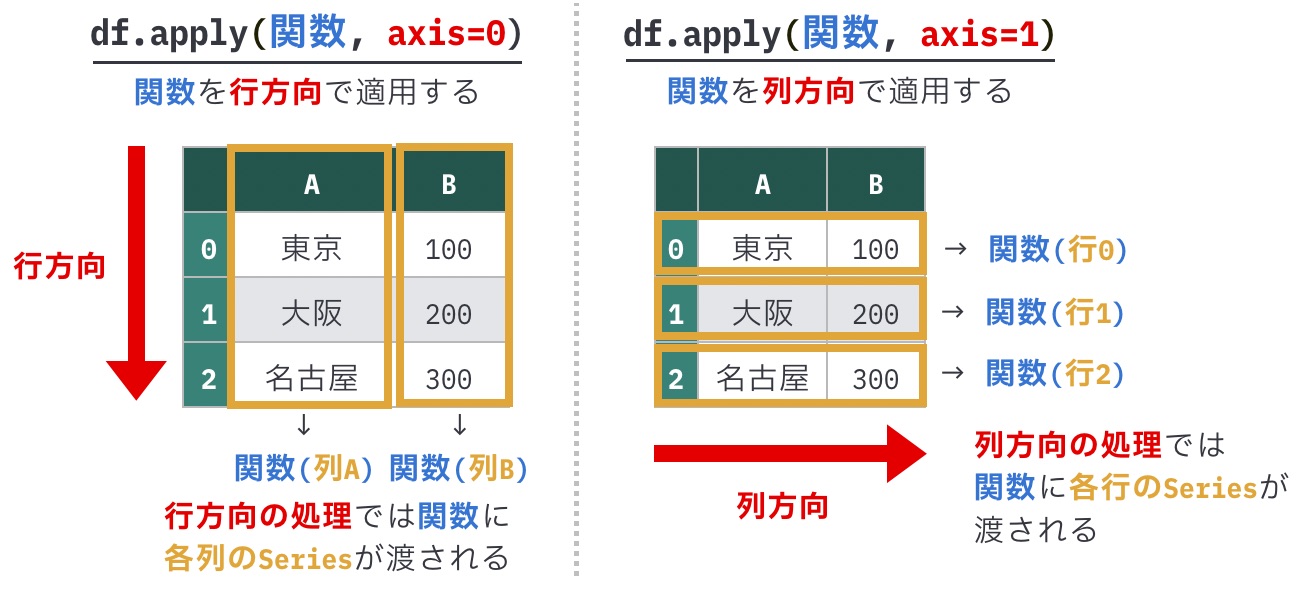
df.apply(関数, axis=処理の方向)今まではdf[“X”].map()など列を指摘してきたが、今回からは全体を対象とする
DataFrameのapply()で適用する関数では、第1引数に行または列のSeriesが渡されます。
引数axisは、処理が適用される軸を表しています。デフォルトでは0になります。
0: 行方向の処理。関数の第1引数には列のSeriesが渡される(次の問題で説明)1: 列方向の処理。関数の第1引数には行のSeriesが渡される(今回の問題で説明)
引数axisはpandasの他のメソッドでも使われる引数で、処理の方向を指定します。共通して0 なら行方向、1 なら列方向の処理になりますが、apply()の場合「行方向の処理 = 列ごとに処理する」「列方向の処理 = 行ごとに処理する」という若干混乱しやすい仕様になっているため、注意しましょう。
具体的な例を見てみましょう。次のような顧客ごとの支払い総額のデータについて考えてみます。
列経過日数 は「最後に購入した日からの経過日数」です。この数字が大きいほど、最近買い物をしていない顧客ということになります。
| 顧客番号 | 支払い総額 | 経過日数 | |
|---|---|---|---|
| 0 | user1 | 8000 | 15 |
| 1 | user2 | 32000 | 190 |
| 2 | user3 | 150000 | 32 |
次のようなルールで顧客区分を分けたいとします。
経過日数が180日以上の場合は、支払い総額の値に関わらず離脱顧客とする経過日数が180日未満の場合は、支払い総額が10万円未満なら普通顧客、10万円以上なら優良顧客とする
列経過日数と列支払い総額の値が必要なので、SeriesではなくDataFrameのapply()を使う必要があります。
このルールをコードで表現すると、次のようになります。
def categorize(row):
# 顧客区分を求める関数
# 引数rowには各行のSeriesが渡される
if row["経過日数"] >= 180:
return "離脱顧客"
if row["支払い総額"] >= 100000:
return "優良顧客"
else:
return "普通顧客"冒頭で説明したように、DataFrameのapply()で適用する関数では、第1引数にSeries型の値が渡されます。引数axisで1を指定した場合は、各行に相当するSeriesが渡されます。関数内では row[列名] とすることで各列の値を参照できます。
# 関数を行ごとに適用(=列方向の処理)
df.apply(categorize, axis=1)0 普通顧客
1 離脱顧客
2 優良顧客
dtype: object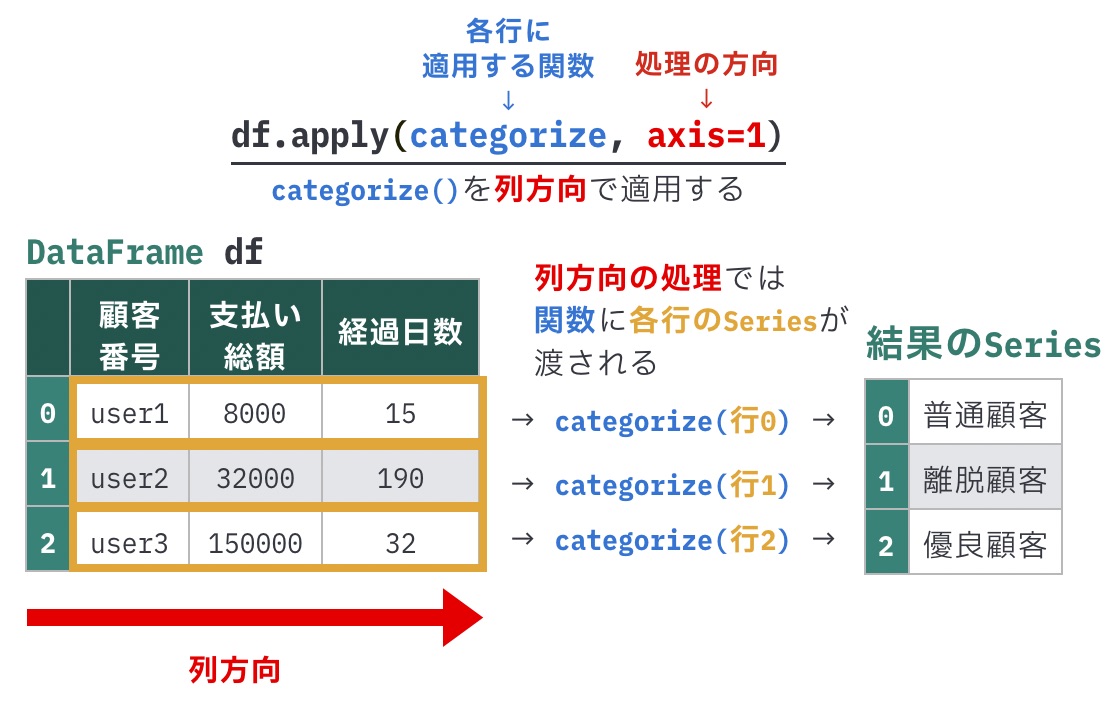
演習
import pandas as pd
# データの読み込み
df = pd.read_csv("dataset/payment_2.csv")
df| 顧客番号 | 支払い総額 | 経過日数 | |
|---|---|---|---|
| 0 | user1 | 8000 | 15 |
| 1 | user2 | 32000 | 190 |
| 2 | user3 | 150000 | 32 |
列”支払い総額_単位あり”の追加
apply()関数の使い方の基本を確認するために、まずは簡単な例からやってみましょう。
列支払い総額の末尾に”円”を追加してみます。1つの列の値しか使わないためSeriesのapply()でも実装できますが、あえてDataFrameのapply()を使う場合、次のように記述します。
def append_yen(row):
# 引数rowには、各行に相当するSeriesが渡される
# そのため、row[列名]とすると指定した列の値を参照できる
return f"{row['支払い総額']}円"
df.apply(append_yen, axis=1)数値+値を追加するときは、return f”{row[‘支払い総額’]}円”
0 8000円 1 32000円 2 150000円 dtype: object
適用される関数の第1引数には、各行のSeriesが渡されます。
試しに、次のように引数で渡された値をprint()で表示してみましょう。 各行に相当するSeriesが引数rowに渡されていることが確認できます。
def append_yen_for_debug(row):
print(row) # ★追加
print("======") # ★追加
return f"{row['支払い総額']}円"
df.apply(append_yen_for_debug, axis=1)顧客番号 user1 支払い総額 8000 経過日数 15 Name: 0, dtype: object ====== 顧客番号 user2 支払い総額 32000 経過日数 190 Name: 1, dtype: object ====== 顧客番号 user3 支払い総額 150000 経過日数 32 Name: 2, dtype: object
apply()を使っただけでは元のdfは変更されないので、実行結果を新しい列として追加します。
# 関数を適用した結果を新しい列として追加
df["支払い総額_単位あり"] = df.apply(append_yen, axis=1)
df| 顧客番号 | 支払い総額 | 経過日数 | 支払い総額_単位あり | |
|---|---|---|---|---|
| 0 | user1 | 8000 | 15 | 8000円 |
| 1 | user2 | 32000 | 190 | 32000円 |
| 2 | user3 | 150000 | 32 | 150000円 |
列”顧客区分”の追加
次に、より実践的な例として、列経過日数と列支払い総額によって顧客区分を求めてみましょう。
まずは、顧客区分を求める関数を定義します。
def categorize(row):
# 顧客区分を求める関数
if row["経過日数"] >= 180:
return "離脱顧客"
if row["支払い総額"] < 100000:
return "普通顧客"
else:
return "優良顧客"作成した関数categorize()を、apply()を使ってdfに適用します。
今回は複数の列を使った処理を行ごと行いたいため、引数axisに1(列方向)を指定します。 こうすることで、categorize()の引数rowには各行のSeriesが渡されます。
# 実行結果を新しい列として追加
df["顧客区分"] = df.apply(categorize, axis=1)
df| 顧客番号 | 支払い総額 | 経過日数 | 支払い総額_単位あり | 顧客区分 | |
|---|---|---|---|---|---|
| 0 | user1 | 8000 | 15 | 8000円 | 普通顧客 |
| 1 | user2 | 32000 | 190 | 32000円 | 離脱顧客 |
| 2 | user3 | 150000 | 32 | 150000円 | 優良顧客 |
簡単にdfに文字や数字を追加する方法
df["新分類"]= df["支払い総額"].astype(str)+"顧客" + str(2)
df| 顧客番号 | 支払い総額 | 経過日数 | 支払い総額_単位あり | 顧客区分 | 新分類 | |
|---|---|---|---|---|---|---|
| 0 | user1 | 8000 | 15 | 8000円 | 普通顧客 | 8000顧客2 |
| 1 | user2 | 32000 | 190 | 32000円 | 離脱顧客 | 32000顧客2 |
| 2 | user3 | 150000 | 32 | 150000円 | 優良顧客 | 150000顧客2 |
ここでstr(df[“支払い総額”])とすると、すべての列が代入される。
普通にdf[“支払い総額”])とだけ入れると、エラーが発生する
数字はstr()と定義を入れてあげる

コメント