

データ分析では、複数の項目でグループ化したいこともあります。たとえば、次のようなケースです。
- テストの平均点を、教科・クラス別で出したい
- A組の国語、A組の数学、B組の国語、B組の数学……など
- 身長と体重の統計量を、性別・年齢ごとに出したい
- 10代女性、10代男性、20代女性、20代男性……など
このような場合、groupby()に 列名のリスト を渡すと、複数列でグループ化できます。
# 複数の列の値に応じてグループ化
df.groupby(列名のリスト)具体的な例を見てみましょう。次のような試験結果のデータについて考えます。生徒ごとに、国語・数学の点数がそれぞれ1行ずつ格納されています。
生徒ID | クラス | 教科 | 点数 |
|---|---|---|---|
| ST001 | 1-A | 国語 | 60 |
| ST001 | 1-A | 数学 | 90 |
| ST002 | 1-A | 国語 | 87 |
| ST002 | 1-A | 数学 | 98 |
| ST003 | 1-B | 国語 | 66 |
| ST003 | 1-B | 数学 | 79 |
| ST004 | 1-A | 国語 | 72 |
| ST004 | 1-A | 数学 | 81 |
| ST005 | 1-B | 国語 | 74 |
| ST005 | 1-B | 数学 | 42 |
| ST006 | 1-B | 国語 | 67 |
| ST006 | 1-B | 数学 | 78 |
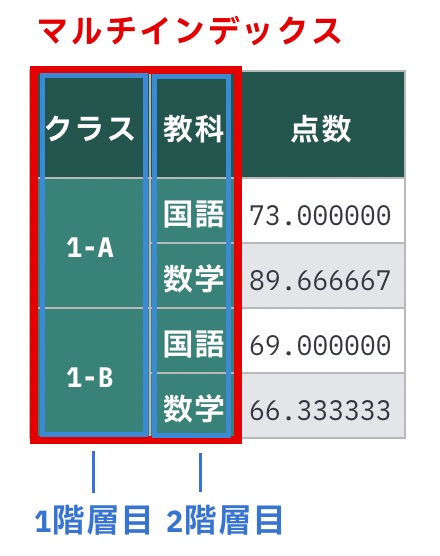
たとえば列クラスと列教科ごとにグループ化して平均点を計算したい場合、次のように記述します。
# 列「クラス」「教科」でグループ化
grouped = df.groupby(["クラス", "教科"])
# クラス x 教科ごとに平均値を計算
grouped.mean()| 点数 | ||
|---|---|---|
| クラス | 教科 | |
| 1-A | 国語 | 73.000000 |
| 数学 | 89.666667 | |
| 1-B | 国語 | 69.000000 |
| 数学 | 66.333333 |
複数の項目でグループ化するので、結果の行名は複数の階層になります。このような複数階層の行名を持つインデックスのことを マルチインデックス と呼びます。
ここでは、「複数の項目でグループ化すると、結果のインデックスが2階層になる」と言う点だけ分かっていれば大丈夫です。
複数の列でグループ化しても、結果はDataFrameGroupByです。そのため、1つの列でグループ化した時と同様agg()やtransform()、filter()などの集約・変換・抽出に関するメソッドが使えます。
演習
まずは、今回使う試験結果のデータを読み込みましょう。1行あたり1生徒のデータで、所属するクラス・教科・試験の点数を表す列があります。In [1]:
import pandas as pd
# 試験結果のデータを読み込み
df = pd.read_csv("dataset/score.csv", index_col="生徒ID")
# 先頭5行を確認
df.head()
Out[1]:
| クラス | 教科 | 点数 | |
|---|---|---|---|
| 生徒ID | |||
| ST001 | 1-A | 国語 | 70 |
| ST001 | 1-A | 数学 | 97 |
| ST002 | 1-B | 国語 | 78 |
| ST002 | 1-B | 数学 | 91 |
| ST003 | 1-A | 国語 | 88 |
本題に入る前に、復習としてまず各教科の全生徒の平均点 を計算してみましょう。ここまでのクエストで学んだのと同様に、groupby()を使って列教科ごとにグループ化し、mean()で平均点を計算します。In [2]:
# 教科ごとの平均値を計算
mean_df = df.groupby("教科").mean()
mean_df
Out[2]:
| 点数 | |
|---|---|
| 教科 | |
| 国語 | 78.6 |
| 数学 | 92.3 |
(1) 各教科のクラスごとの平均点
次に、各教科の平均点をクラスごとに出してみましょう。
groupby()で複数の列を指定すると、複数の項目でグループ化できます。実際に教科とクラスを指定すると、集約結果のインデックスが教科とクラスになり、各グループの平均点が計算されることがわかります。In [3]:
# 教科 x クラスごとにグループ化 grouped = df.groupby(["教科", "クラス"]) # グループごとに平均値を計算 mult_mean_df = grouped.mean() mult_mean_df
Out[3]:
| 点数 | ||
|---|---|---|
| 教科 | クラス | |
| 国語 | 1-A | 77.6 |
| 1-B | 79.6 | |
| 数学 | 1-A | 91.2 |
| 1-B | 93.4 |
(2) 各教科のクラスごとの最低点・最高点・平均点
複数の項目でグループ化した場合も、1つの項目でグループ化した時と同様、結果はDataFrameGroupByオブジェクトです。そのため、ここまでのクエストで学んだ集約・変換・選択の機能が使えます。
たとえば、集約で使う agg() を使って複数の集約値を計算することも可能です。次のコードでは、最小値、最大値、平均値を一括で計算しています。In [4]:
# 教科 x クラスごとに最小値、最大値、平均値を出す mult_agg_df = grouped.agg(["min", "max", "mean"]) mult_agg_df
Out[4]:
| 点数 | ||||
|---|---|---|---|---|
| min | max | mean | ||
| 教科 | クラス | |||
| 国語 | 1-A | 70 | 88 | 77.6 |
| 1-B | 65 | 94 | 79.6 | |
| 数学 | 1-A | 87 | 97 | 91.2 |
| 1-B | 78 | 100 | 93.4 |
クエスト「グループ化でできることを知ろう」では、get_group(グループ名)と書くと、指定したグループのデータを取得できることを学びました。
複数項目でグループ化した場合、グループ名はタプルで指定します。たとえば「1-Aの数学のデータ」を取得する場合は、次のように(“数学”, “1-A”)を指定します。In [5]:
# 数学の1-Aグループを取得
grouped.get_group(("数学", "1-A"))
Out[5]:
| クラス | 教科 | 点数 | |
|---|---|---|---|
| 生徒ID | |||
| ST001 | 1-A | 数学 | 97 |
| ST003 | 1-A | 数学 | 92 |
| ST005 | 1-A | 数学 | 87 |
| ST007 | 1-A | 数学 | 92 |
| ST009 | 1-A | 数学 | 88 |
補足
2つの項目でグループ化して集約したい場合、pivot_table()も便利です。
# ピボットテーブルを作成する
df.pivot_table(index=1軸目の列, columns=2軸目の列, values=集約したい値)たとえば写経のデータを使って縦軸に「クラス」、横軸に「教科」、値を「点数の平均点」にしたい場合、次のように書きます。
# クラス x 教科ごとに点数の平均を求める
df.pivot_table(index="クラス", columns="教科", values="点数")クラス | 国語 | 数学 |
|---|---|---|
| 1-A | 77.6 | 91.2 |
| 1-B | 79.6 | 93.4 |
1-Aの国語の平均点が77.6点になっており、写経でgroupby()を使って計算した結果と同じであることがわかります。
pivot_table()はデフォルトでは平均を求めますが、引数aggfuncで他の集約方法を指定することも可能です。

コメント