

前問では、df.loc[比較結果]とすることで特定の条件で行を取得できることを学びました。
同じ記述を使って、次のように新しい値に更新もできます。
df.loc[比較結果] = 新しい値 =1つは定義| Name | Age | |
|---|---|---|
| 0 | Alice | 17 |
| 1 | Bob | 24 |
| 2 | Carol | 29 |
下記では、「Ageが20以上の行」の行(2行目と3行目)を更新しています。
df.loc[df.Age >= 20] = [["Ben", 14], ["Chuck", 15]]
df| Name | Age | |
|---|---|---|
| 0 | Alice | 17 |
| 1 | Ben | 14 |
| 2 | Chuck | 15 |
行と同様に、列も条件による絞り込みができます。
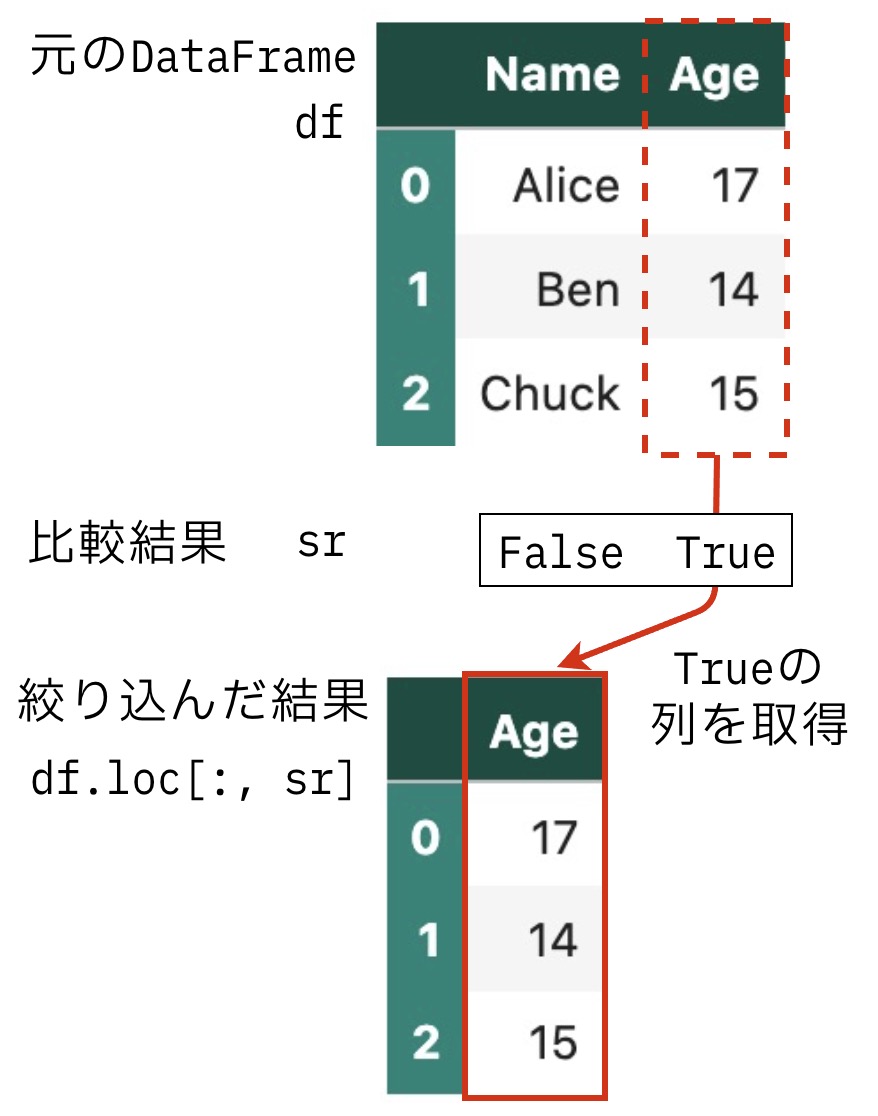
例として「列の型がint」の列は下記のようにして取得できます。列の場合は、df.loc[:, 比較結果]とします。
sr = df.dtypes == int # 比較結果 ==は条件のこと
df.loc[:, sr] # srの要素がTrueの列を抜き出す| Age | |
|---|---|
| 0 | 17 |
| 1 | 14 |
| 2 | 15 |
また、df.loc[行の比較結果, 列の比較結果]のように行と列の両方に条件を指定することもできます。
locはlocationの略。
ilocはindex locationの略 なので、数字でないとだめ。
たとえば、「Ageが16以下の列Name」は下記のように書きます。
# 行を条件で、列を列名で絞り込み
df.loc[df.Age <= 16, "Name"]
df.loc[条件の行,条件の列]また、「Ageが16以下の列NameをBobとCarolに更新する」は下記のように書けます。
# 行を条件で、列を列名で絞り込んで更新
df.loc[df.Age <= 16, "Name"] = ["Bob", "Carol"]ilocは、df.iloc[行の比較結果, 列の比較結果]のように比較結果を使うことはできません。条件を指定したいときは、ilocではなくlocを使いましょう。
| Name | Height | Weight | |
|---|---|---|---|
| 0 | 佐藤 | 172 | 53 |
| 1 | 田中 | 160 | 50 |
| 2 | 鈴木 | 165 | 58 |
| 3 | 長谷川 | 160 | 65 |
df.loc[df.Weight >= 55, "Height"] = 167
df=は一つ。”Height”の前のdfはいらない。
| Name | Height | Weight | |
|---|---|---|---|
| 0 | 佐藤 | 172 | 53 |
| 1 | 田中 | 160 | 50 |
| 2 | 鈴木 | 167 | 58 |
| 3 | 長谷川 | 167 | 65 |

コメント