

- 列
支払い総額の値に応じて、複雑な条件で顧客区分を求める。 - 列
住所の文字列から、都道府県の部分だけを抽出する。 - 列
受験科目の値に応じて、合格点の閾値を変えて合否を求める。
このような、より柔軟なデータ処理が必要なケースではapply()が便利です。
apply()は指定した関数を列または行に一括で適用するメソッドです。DataFrameとSeriesの両方で使えます。
Seriesのapply()では、「列支払い総額に応じて顧客を分ける」など、1つの列の値を使った処理ができます。
DataFrameのapply()では、「列支払い総額と列最終支払いからの日数に応じて顧客を分ける」など、複数の列や行の値を使った処理ができます。
apply()では自分で定義した関数も使えるので、柔軟なデータ加工が可能です。for文で1行ずつデータを処理するのに比べて、処理が高速で、記述も簡潔になります。
Seriesのapply
Seriesのapply()は、指定した関数を列の値に一括で適用します。実行結果はSeriesです。
# 指定した列の値に関数を適用
df[列名].apply(関数)具体的な例を見てみましょう。
次のような顧客ごとの支払い総額のデータについて考えてみます。
| 顧客番号 | 支払い総額 | |
|---|---|---|
| 0 | user1 | 8000 |
| 1 | user2 | 32000 |
| 2 | user3 | 150000 |
| 3 | user4 | 0 |
「列支払い総額が10万円以上の場合は"優良顧客"、それ以外は"普通顧客"とする」場合、apply()を使うと次のように書けます。
def categorize(payment):
# 顧客区分を求める関数
if payment >= 100000:
return "優良顧客"
else:
return "普通顧客"
# categorize()関数を列「支払い総額」に適用
df["支払い総額"].apply(categorize)Seriesのapply()に適用する関数の第1引数には、適用対象の列の値が渡されます。
そのためcategorize()には、第1引数paymentで支払い総額の値を受け取って、戻り値で顧客区分を返すような処理を書いています。
上記のコードを実行すると、行ごとにcategorize()を適用した結果が、次のようにSeriesの形で得られます。
0 普通顧客
1 普通顧客
2 優良顧客
3 普通顧客
Name: 支払い総額, dtype: object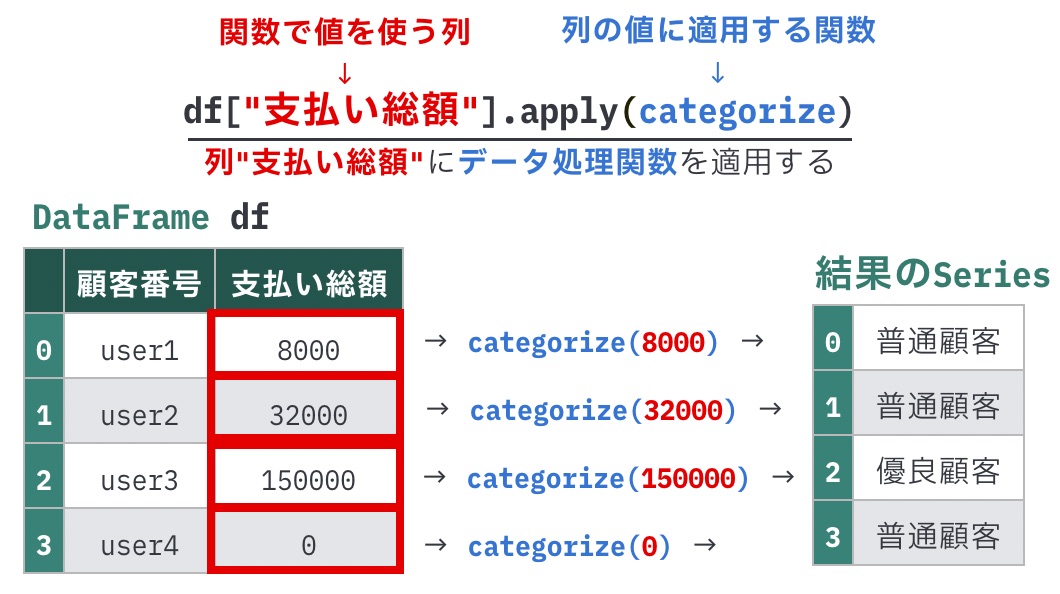
今回は説明のため簡単な例で紹介しましたが、適用する関数の内容によってより複雑な処理も可能です。
先ほどの例では、apply()で指定する関数は第1引数だけでした。第1引数には、指定した列の値が渡されます。
では、列の値以外に引数を持つ関数の場合はどのようにすればよいでしょうか。
たとえば次の関数では、先ほどの関数に引数thresholdが追加されており、優良顧客かどうかの閾値を指定できるようにしています。
# 支払いの閾値を引数で指定可能にした関数
# 引数paymentには、列「支払い総額」の値が入る
# 引数thresholdは、apply()実行時に指定する
def categorize(payment, threshold):
# 顧客区分を求める関数
if payment >= threshold:
return "優良顧客"
else:
return "普通顧客"列の値以外に引数を持つ関数の場合、次のようにapply()を使うとき引数を一緒に指定します。
# 2万円を閾値に指定
df["支払い総額"].apply(categorize, threshold=20000) 0 普通顧客
1 優良顧客
2 優良顧客
3 普通顧客
Name: 支払い総額, dtype: object
キーワード引数の場合は、上記のようにapply()呼び出し時にキーワード付きで指定します。
位置引数の場合は、次のように引数argsにタプルを使って指定します。
位置引数とは:引数を指定して関数を呼び出す場合、呼び出し側で指定した引数の値が順番に関数側で引数のところに定義した変数に順番に代入されます。 このような形式を位置引数と呼びます。 位置引数の場合、引数を記載した順番に従って引数の値が渡されますので、実引数1は仮引数1へ渡され、実引数2は仮引数2へ渡されます。
df[列名].apply(関数, args=(第2引数に渡す値, 第3引数に渡す値, ... , 第N引数に渡す値)) 先ほどのサンプルコードをキーワードではなく位置による呼び出し方に書き直すと、次のようになります。
# 2万円を閾値に指定
# キーワード引数ではなく、位置引数として指定する場合
df["支払い総額"].apply(categorize, args=(20000,)) 演習
import pandas as pd
# 顧客ごとの支払い総額データの読み込み
df = pd.read_csv("dataset/payment_1.csv")
df| 顧客番号 | 支払い総額 | |
|---|---|---|
| 0 | user1 | 8000 |
| 1 | user2 | 32000 |
| 2 | user3 | 150000 |
| 3 | user4 | 0 |
def categorize (payment, threshold):
if payment ==0:
return "初回顧客"
elif payment<=threshold:
return "普通顧客"
else:
return "優良顧客"
# 実行結果を新しい列として追加
df["顧客区分_10万円"] = df["支払い総額"].apply(categorize, threshold=100000)
dfelifを使いながら、スマートに条件を設定する
| 顧客番号 | 支払い総額 | 顧客区分_10万円 | |
|---|---|---|---|
| 0 | user1 | 8000 | 普通顧客 |
| 1 | user2 | 32000 | 普通顧客 |
| 2 | user3 | 150000 | 優良顧客 |
| 3 | user4 | 0 | 初回顧客 |
# 実行結果を新しい列として追加
df["顧客区分_2万円"] = df["支払い総額"].apply(categorize, threshold=20000)
df| 顧客番号 | 支払い総額 | 顧客区分_10万円 | 顧客区分_2万円 | |
|---|---|---|---|---|
| 0 | user1 | 8000 | 普通顧客 | 普通顧客 |
| 1 | user2 | 32000 | 普通顧客 | 優良顧客 |
| 2 | user3 | 150000 | 優良顧客 | 優良顧客 |
| 3 | user4 | 0 | 初回顧客 | 初回顧客 |

コメント