

前回の問題では、read_csv()の基本の動作について学びました。
前問で扱ったCSVファイルには、列名一覧に相当するヘッダーが1行目にありました。しかし、実務で扱うCSVファイルではヘッダーがない場合もあります。

read_csv()では、引数headerでヘッダーを指定できます。
たとえばヘッダーがないCSVファイルの場合、引数headerにNoneを指定します。このとき、列名一覧には0から始まる通し番号が自動で割り当てられます。
# ヘッダーがないCSVファイルの読み込み
df = pd.read_csv(ファイルパス, header=None)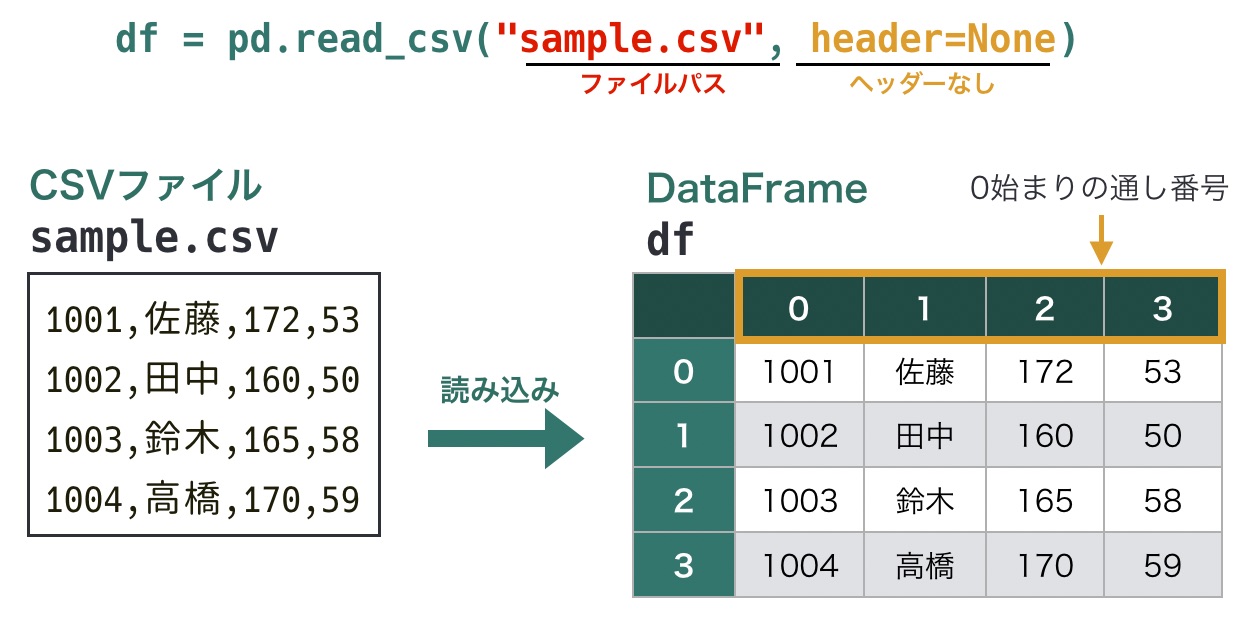
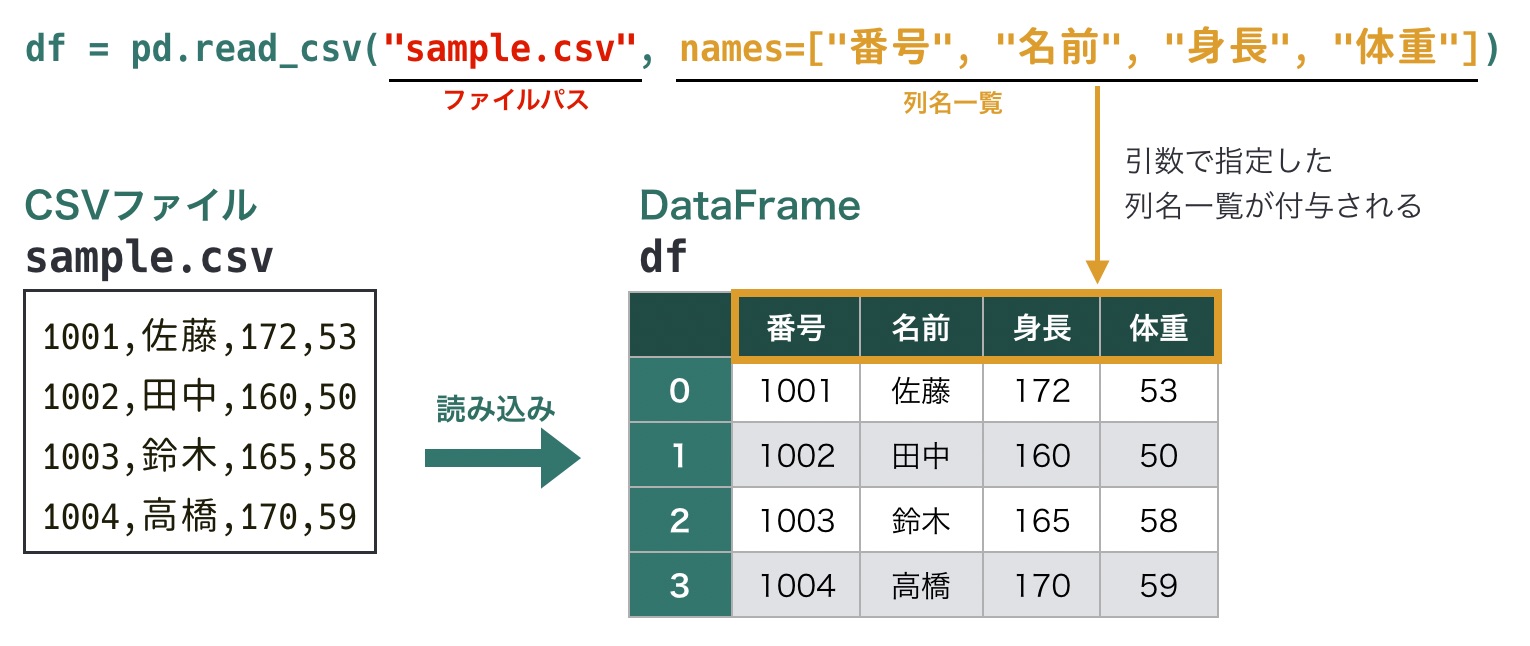
また引数namesを使うと、ヘッダーがないCSVファイルに任意の列名を付与して読み込みます。引数namesを指定すると、引数headerは自動的にNoneを指定した場合と同じ動作になるため、引数headerと引数namesを同時に指定する必要はありません。
# 任意の列名を付与して読み込み
df = pd.read_csv(ファイルパス, names=列名のリスト)
演習
まずは、catコマンドを使って今回使うファイルの中身を確認しましょう。
今回使うファイルは、列名が書かれたヘッダーがなく、1行目から4行目までデータが格納されています。
!cat dataset/physical_measurement_no_header.csv1001,佐藤,172,53
1002,田中,160,50
1003,鈴木,165,58
1004,高橋,170,59まずは、何もオプションを指定せずに読み込んでみましょう。デフォルトだとCSVファイルの1行目を列名一覧として読み込むため、以下のようにおかしな結果になってしまいます。
import pandas as pd
# デフォルトのまま読み込み
df_default = pd.read_csv("dataset/physical_measurement_no_header.csv")
df_default| 1001 | 佐藤 | 172 | 53 | |
|---|---|---|---|---|
| 0 | 1002 | 田中 | 160 | 50 |
| 1 | 1003 | 鈴木 | 165 | 58 |
| 2 | 1004 | 高橋 | 170 | 59 |
ヘッダーがない場合、引数headerでNoneを指定しましょう。実行すると、列名一覧に0から始まる通し番号が自動で割り当てられることがわかります。
# ヘッダーがないことを指定して読み込み
df_no_header = pd.read_csv('dataset/physical_measurement_no_header.csv', header=None)
df_no_header| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 1001 | 佐藤 | 172 | 53 |
| 1 | 1002 | 田中 | 160 | 50 |
| 2 | 1003 | 鈴木 | 165 | 58 |
| 3 | 1004 | 高橋 | 170 | 59 |
また、引数namesに列名のリストを渡すことで、列名を自分でつけることもできます。なお引数namesを指定した場合、自動的にheader=Noneとして扱われるため、引数headerの指定は不要です。
実行すると、列名一覧に引数namesで指定した列名が反映されていることがわかります。
# 列名を自分でつけて読み込み
df_names = pd.read_csv(
"dataset/physical_measurement_no_header.csv",
names=["StudentID", "Name", "Height", "Weight"], # 列名のリスト
)
df_names| StudentID | Name | Height | Weight | |
|---|---|---|---|---|
| 0 | 1001 | 佐藤 | 172 | 53 |
| 1 | 1002 | 田中 | 160 | 50 |
| 2 | 1003 | 鈴木 | 165 | 58 |
| 3 | 1004 | 高橋 | 170 | 59 |

コメント