

「変換」ではグループごとに 個々のデータ に対して処理を行う点が特徴です。そのため、次のようにグループごとにデータの個数分の結果が出ます。
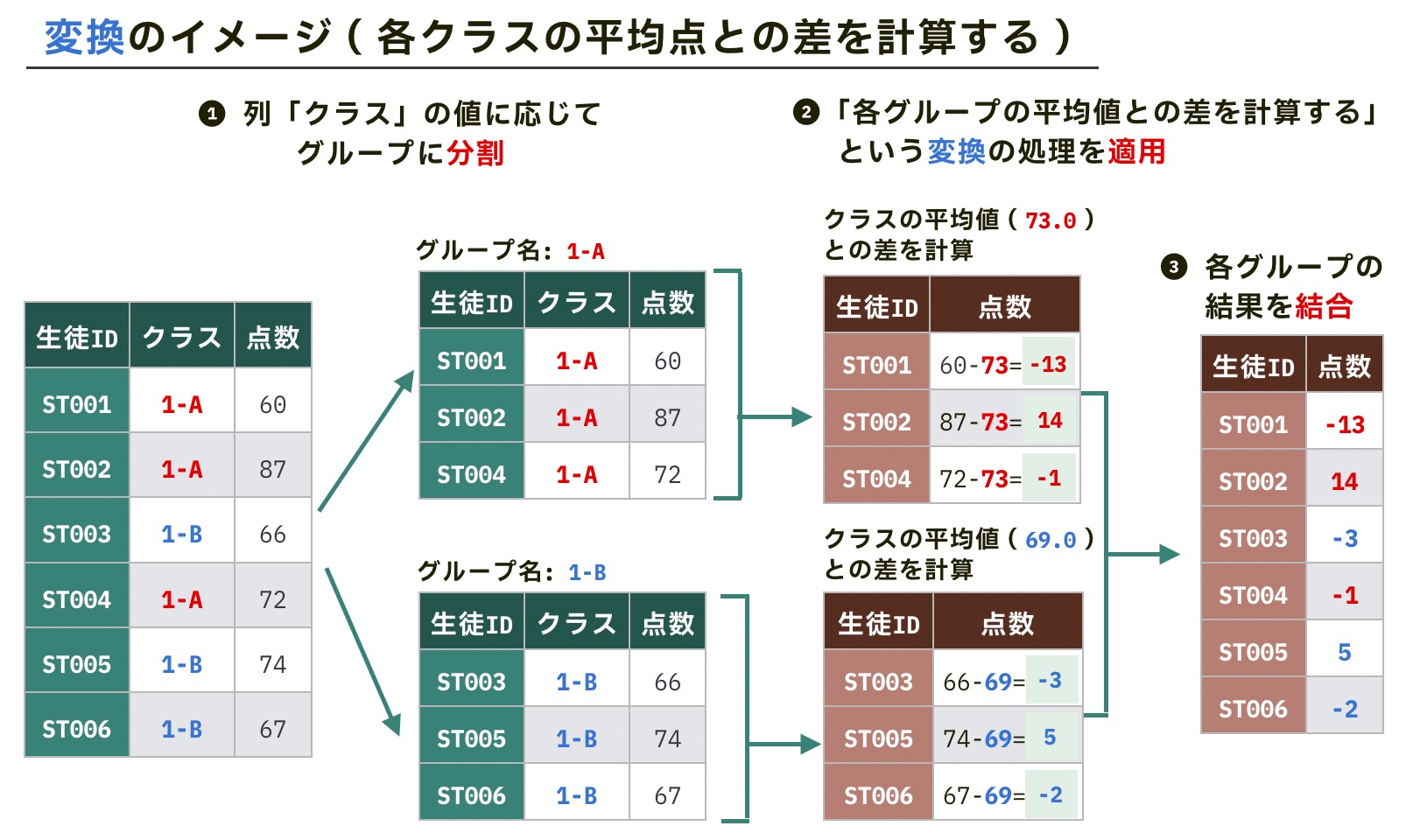
変換処理の方法
次のようにgroupby()の結果(DataFrameGroupByオブジェクト)と変換メソッドを組み合わせることで、グループごとのデータの変換ができます。
# 指定した列名でグループ化
grouped = df.groupby(列名)
# グループごとにデータを変換する
grouped.変換メソッド()DataFrameGroupByには、いろいろな変換メソッドがあります。基本的に、DataFrameで使えたメソッドはDataFrameGroupByでも使えます。
| 変換メソッド | 説明 | 集約メソッド | 説明 |
|---|---|---|---|
rank() | グループ内の順位を計算 | cumcount() | グループ内で0始まりの通し番号をふる(※) |
cumsum() | グループ内で累積和を計算 | cumprod() | グループ内で累積積を計算 |
diff() | グループ内で階差を計算 | pct_change() | グループ内で変化率を計算 |
※ cumcount()はDataFrameGroupByだけで使えます(DataFrameでは使えません)。
具体的な例として、本問ではrank()の使い方を紹介します。
DataFrameGroupByのrank()
パート「データ加工」のクエスト「よくある計算をしてみよう」では、DataFrameのrank()を使って順位を計算する方法を学びました。DataFrameGroupByの同名のメソッドを使うと、これらの処理をグループごとに適用できます。
DataFrameGroupByオブジェクトのrank()は次のようにして使います。
# 指定した列名ごとにグループ化
grouped = df.groupby(列名)
# グループごとに順位を計算
grouped.rank()DataFrameのrank()同様、DataFrameGroupByオブジェクトのrank()でも、引数ascendingや引数methodが使えます。
生徒ID | クラス | 点数 | 学習時間(分) |
|---|---|---|---|
| ST001 | 1-A | 60 | 232 |
| ST002 | 1-A | 87 | 345 |
| ST003 | 1-B | 66 | 180 |
| ST004 | 1-A | 72 | 22 |
| ST005 | 1-B | 74 | 120 |
| ST006 | 1-B | 58 | 215 |
クラスごとに、各列の順位を計算してみましょう。値が大きい方から1位、2位……と順位をつける場合、引数ascendingでFalseを指定します。
# 列「クラス」でグループ化
grouped = df.groupby("クラス")
# グループごとに、大きい順で順位を計算
grouped.rank(ascending=False)生徒ID | 点数 | 学習時間(分) |
|---|---|---|
| ST001 | 3.0 | 2.0 |
| ST002 | 1.0 | 1.0 |
| ST003 | 2.0 | 2.0 |
| ST004 | 2.0 | 3.0 |
| ST005 | 1.0 | 3.0 |
| ST006 | 3.0 | 1.0 |
グループごとに、列点数と列学習時間(分)でそれぞれ大きい順に順位が出されていることがわかります。
たとえば列点数では、1-Aの生徒(ST001、ST002、ST004)の中では、1位がST002(87点)、2位がST004(72点)、3位がST001(60点)になっています。
演習
import pandas as pd
# 試験結果のデータを読み込み
df = pd.read_csv("dataset/score_study_time.csv", index_col="生徒ID")
# 先頭5行を確認
df.head()
| クラス | 点数 | 学習時間(分) | |
|---|---|---|---|
| 生徒ID | |||
| ST001 | 1-A | 48.0 | 226 |
| ST002 | 1-A | 0.0 | 24 |
| ST003 | 1-B | 80.0 | 271 |
| ST004 | 1-A | NaN | 45 |
| ST005 | 1-A | 68.0 | 271 |
今回はクラスごとに順位を求めるので、groupby()を使ってクラスごとにグループ化します。
# 列「クラス」でグループ化
grouped = df.groupby("クラス")
各グループ内での順位はrank()を使って求められます。DataFrameのrank()同様、DataFrameGroupByのrank()も引数ascendingで順位付けを昇順でするか降順でするか指定できます。今回は大きい順に順位付けをしたいので、False(降順)を指定します。In [3]:
# クラス内での順位を計算する(降順で順位付け) rank_df = grouped.rank(ascending=False) # 結果の先頭5行を確認 rank_df.head()
| 点数 | 学習時間(分) | |
|---|---|---|
| 生徒ID | ||
| ST001 | 8.0 | 8.0 |
| ST002 | 9.0 | 10.0 |
| ST003 | 2.0 | 3.0 |
| ST004 | NaN | 9.0 |
| ST005 | 6.0 | 6.0 |
順位付けの結果を、新しい列として元のdfに追加しましょう。
# 変換の結果を新しい列として追加 df[["クラス内順位_点数", "クラス内順位_学習時間"]] = rank_df # 結果の先頭5行を確認 df.head()
| クラス | 点数 | 学習時間(分) | クラス内順位_点数 | クラス内順位_学習時間 | |
|---|---|---|---|---|---|
| 生徒ID | |||||
| ST001 | 1-A | 48.0 | 226 | 8.0 | 8.0 |
| ST002 | 1-A | 0.0 | 24 | 9.0 | 10.0 |
| ST003 | 1-B | 80.0 | 271 | 2.0 | 3.0 |
| ST004 | 1-A | NaN | 45 | NaN | 9.0 |
| ST005 | 1-A | 68.0 | 271 | 6.0 | 6.0 |
確認のため、クラスが1-Aのデータの結果を見てみましょう。わかりやすいように、sort_values()を使って列点数を並び替えて確認します。列クラス内順位_点数を見ると、クラス1-A内で最も点数が高い生徒ST011が1位、次に点数が高い生徒ST020が2位になっていることがわかります。
# 1-Aのデータを列「点数」でソート
df[df["クラス"] == "1-A"].sort_values("点数")
特定の分類を出す方法
| クラス | 点数 | 学習時間(分) | クラス内順位_点数 | クラス内順位_学習時間 | |
|---|---|---|---|---|---|
| 生徒ID | |||||
| ST002 | 1-A | 0.0 | 24 | 9.0 | 10.0 |
| ST001 | 1-A | 48.0 | 226 | 8.0 | 8.0 |
| ST007 | 1-A | 49.0 | 236 | 7.0 | 7.0 |
| ST005 | 1-A | 68.0 | 271 | 6.0 | 6.0 |
| ST019 | 1-A | 78.0 | 326 | 5.0 | 3.0 |
| ST017 | 1-A | 81.0 | 355 | 4.0 | 2.0 |
| ST012 | 1-A | 84.0 | 286 | 3.0 | 5.0 |
| ST020 | 1-A | 90.0 | 301 | 2.0 | 4.0 |
| ST011 | 1-A | 98.0 | 381 | 1.0 | 1.0 |
| ST004 | 1-A | NaN | 45 | NaN | 9.0 |
同様に、クラスが1-Bのデータも確認してみましょう。クラス1-Bの中で最も点数が高い生徒ST014が1位、次に点数が高い生徒ST003が2位になっています。このように、DataFrameGroupByオブジェクトのrank()を使うと、グループごとに順位を計算できます。
# 1-Bのデータを列「点数」でソート
df[df["クラス"] == "1-B"].sort_values("点数")
| クラス | 点数 | 学習時間(分) | クラス内順位_点数 | クラス内順位_学習時間 | |
|---|---|---|---|---|---|
| 生徒ID | |||||
| ST006 | 1-B | 58.0 | 215 | 7.5 | 9.0 |
| ST013 | 1-B | 58.0 | 192 | 7.5 | 10.0 |
| ST015 | 1-B | 62.0 | 220 | 6.0 | 8.0 |
| ST016 | 1-B | 69.0 | 222 | 5.0 | 7.0 |
| ST009 | 1-B | 75.0 | 256 | 4.0 | 4.0 |
| ST008 | 1-B | 79.0 | 334 | 3.0 | 1.0 |
| ST003 | 1-B | 80.0 | 271 | 2.0 | 3.0 |
| ST014 | 1-B | 83.0 | 286 | 1.0 | 2.0 |
| ST010 | 1-B | NaN | 229 | NaN | 5.0 |
| ST018 | 1-B | NaN | 224 | NaN | 6.0 |
なお、rank()はSeriesGroupByオブジェクトでも使えます。特定の列の順位だけを使いたい場合は、こちらを使うとよいでしょう。
# SeriesGroupByオブジェクトのrank()を使う rank_sr = grouped["点数"].rank() rank_sr
Out[7]:
生徒ID ST001 2.0 ST002 1.0 ST003 7.0 ST004 NaN ST005 4.0 ST006 1.5 ST007 3.0 ST008 6.0 ST009 5.0 ST010 NaN ST011 9.0 ST012 7.0 ST013 1.5 ST014 8.0 ST015 3.0 ST016 4.0 ST017 6.0 ST018 NaN ST019 5.0 ST020 8.0 Name: 点数, dtype: float64
rank()の実行結果では元の列名が使われるため、元のデータと混同して分かりにくい場合があります。
たとえば今回の写経のrank()の実行結果では、列名が元データと同じ点数と学習時間(分)になっています。
# クラス内での順位を計算する(降順で順位付け)
rank_df = grouped.rank(ascending=False)
# 結果の先頭5行を確認
rank_df.head()生徒ID | 点数 | 学習時間(分) |
|---|---|---|
| ST001 | 8 | 8 |
| ST002 | 9 | 10 |
| ST003 | 2 | 3 |
| ST004 | NaN | 9 |
| ST005 | 6 | 6 |
このようなときは、add_suffix()が便利です。DataFrameで次のように使うことで、指定した文字列を各列名の末尾に付加 できます。
# 各列名の末尾に、指定した文字列を付加
df.add_suffix(文字列)たとえば今回の写経のデータの場合、次のように書くと列点数は点数_rankに、列学習時間(分)は学習時間(分)_rankに一括で変更できます。
# rank()の結果の列名の末尾に"_rank"という文字列を付与する
grouped.rank(ascending=False).add_suffix("_rank")生徒ID | 点数_rank | 学習時間(分)_rank |
|---|---|---|
| ST001 | 8.0 | 8.0 |
| ST002 | 9.0 | 10.0 |
| ST003 | 2.0 | 3.0 |
| ST004 | NaN | 9.0 |
| … | … | … |

コメント