

分析するためには、BoWをベクトル表現に変える必要があります。
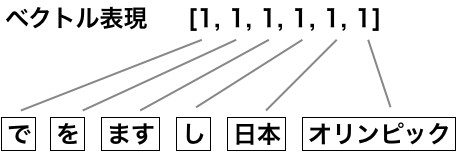
手順は以下のようになります。
- 全単語を求めます
- 全単語の順番を値とする辞書を作成します
- 全単語数の次元数からなる単位行列を作成します
- 辞書形式のBoWを多次元のベクトルに変換します
- 要素は出現数です
%run 2.ipynbCounter({'する': 3, '二': 3, '階': 3, '飛び降りる': 3, '抜かす': 3, 'ある': 3, '時': 2, 'いる': 2, '一': 2, '腰': 2, '事': 2, '人': 2, '親譲り': 1, '無鉄砲': 1, '供': 1, '損': 1, '小学校': 1, '居る': 1, '時分': 1, '学校': 1, '週間': 1, '無闇': 1, '聞く': 1, '知れる': 1, '理由': 1, '新築': 1, '首': 1, '出す': 1, '同級生': 1, '冗談': 1, '威張る': 1, 'そこ': 1, '出来る': 1, '弱虫': 1, 'ー': 1, 'い': 1, '囃す': 1, '小使': 1, '負ぶさる': 1, '帰る': 1, '来る': 1, 'おやじ': 1, '眼': 1, '奴': 1, '云う': 1, '次': 1, '飛ぶ': 1, '見せる': 1, '答える': 1})
0 {'親譲り': 1, '無鉄砲': 1, '供': 1, '時': 2, '損': 1, '...
1 {'親類': 1, 'もの': 1, '西洋': 1, '製': 1, 'ナイフ': 2, ...
2 {'庭': 2, '東': 1, '二': 1, '十': 2, '歩': 1, '行く':...
3 {'鉢': 1, '開く': 1, '頭': 3, 'こっち': 1, '胸': 1, '宛...
4 {'外': 1, 'いたずら': 1, 'やる': 1, '大工': 1, '兼': 1, ...
5 {'おやじ': 2, 'おれ': 2, '可愛がる': 1, 'くれる': 1, '母': ...
6 {'母': 2, '病気': 1, '死ぬ': 4, '二': 1, '三': 1, '日'...
7 {'母': 1, '死ぬ': 1, 'おやじ': 5, '兄': 3, '三': 1, '人...
8 {'時': 1, '仕方': 1, '観念': 1, 'する': 6, '先方': 1, '...
9 {'おれ': 5, '人': 2, '好く': 1, 'れる': 2, '性': 1, 'あ...
10 {'母': 1, '死ぬ': 1, '清': 2, 'おれ': 2, 'がる': 1, '供...
11 {'三': 3, '円': 4, '蝦蟇口': 2, '入れる': 2, '懐': 1, '...
12 {'みなさん': 1, 'ふう': 1, '川': 1, '言う': 2, 'れる': 2,...
13 {'ジョバンニ': 5, 'さん': 2, 'あなた': 1, 'わかる': 1, 'いる'...
14 {'先生': 1, '意外': 1, 'よう': 1, 'カムパネルラ': 1, '見る':...
15 {'ジョバンニ': 2, '赤': 1, 'なる': 3, 'うなずく': 1, 'いつか'...
16 {'天の川': 5, 'ほんとう': 1, '川': 3, '考える': 2, '一つ': ...
17 {'先生': 1, '中': 3, 'たくさん': 2, '光る': 5, '砂': 1, ...
18 {'教室': 2, 'じゅう': 1, '机': 1, '蓋': 1, 'あける': 1, ...
Name: Content, dtype: object
import numpy as np# 全単語を求めます
bowset = {k for bow in bows for k in bow}
print(len(bowset)) # 全単語数641
全単語を求めるための集合の内包表記
641個の単語になります。
※ bowsetの順番は変わることがあります。
print(str(bowset)[:100]){'割れる', '女形', '借りる', '顔', '度', '使う', '小学校', '元来', '半分', '巨', '紐', '肴', '暮す', '台所', '真赤', '天の川', 'もん'
# 全単語の順番を値とする辞書を作成します
bowdc = {s: i for i, s in enumerate(sorted(bowset))}
print(str(bowdc)[:100])上記のように辞書の内包表記でできます。bowsetの順番に依らないようにsorted(bowset)でソートしています。
先頭から値が0, 1, 2, …となります。
{'あう': 0, 'あかり': 1, 'あきらめる': 2, 'あける': 3, 'あげる': 4, 'あたる': 5, 'あと': 6, 'あなた': 7, 'あらす': 8, 'ある': 9,
# 全単語数の次元数からなる単位行列を作成します
I = np.eye(len(bowdc), dtype=int)上記のように単位行列を作成します。
これは、I[i]とすることで、i番目だけが1となる単位ベクトルを取得するのに使います。
# 辞書形式のBoWを多次元のベクトルに変換します
def calc_vec(bow, bowdc, I):
return sum(I[bowdc[k]] * v for k, v in bow.items()).tolist()まずは、I[bowdc[k]]として、各単語に対応する単位ベクトルを求めます。
次に、上記のように、その単位ベクトルと単語の出現数をかけて和を取ります。
bowvec = bows.apply(calc_vec, bowdc=bowdc, I=I)
bowveccalc_vecで、ベクトル表現の計算を行い、結果をbowvecに入れます。
0 [0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 1, 0, 0, 0, ...
1 [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, ...
2 [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, ...
3 [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, ...
4 [0, 0, 0, 0, 0, 0, 0, 0, 1, 3, 0, 0, 1, 0, 0, ...
5 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...
6 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...
7 [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, ...
8 [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, ...
9 [0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, ...
10 [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, ...
11 [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...
12 [0, 0, 0, 0, 3, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, ...
13 [0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, ...
14 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...
15 [1, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, ...
16 [0, 0, 0, 0, 0, 3, 0, 0, 0, 1, 0, 0, 0, 0, 0, ...
17 [0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 1, ...
18 [0, 2, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, ...
Name: Content, dtype: object
コメント