

決定木を組み合わせたランダムフォレストという手法を試してみましょう。
性能が高く、過学習に陥りにくく、スケーラビリティに優れている(並列実行が可能)という特徴があります。
アンサンブル学習とランダムフォレストとは
アンサンブル学習 とは複数のアルゴリズムを組み合わせて、より強い学習モデルを作ろうとする手法の総称です。
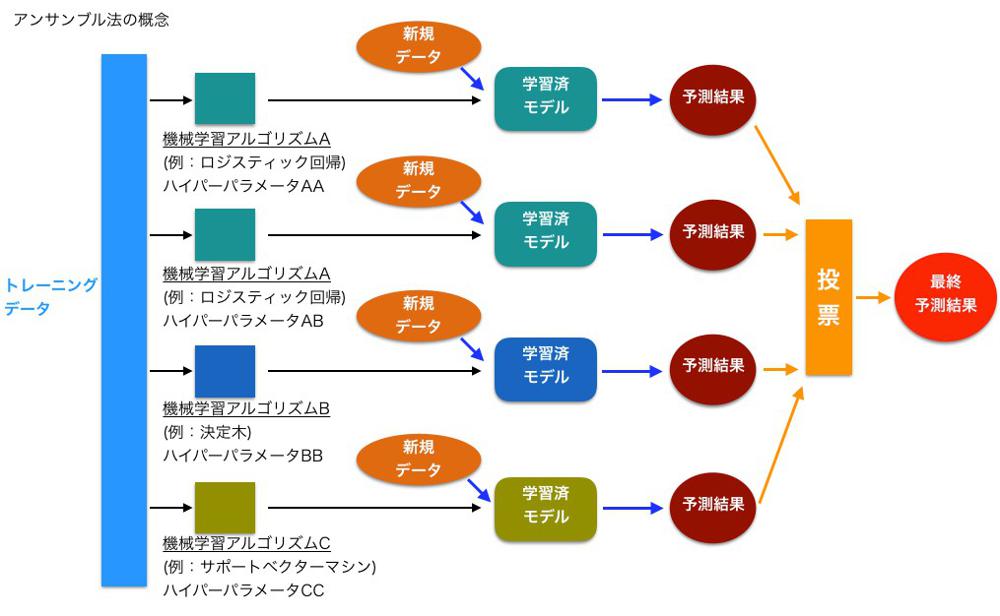
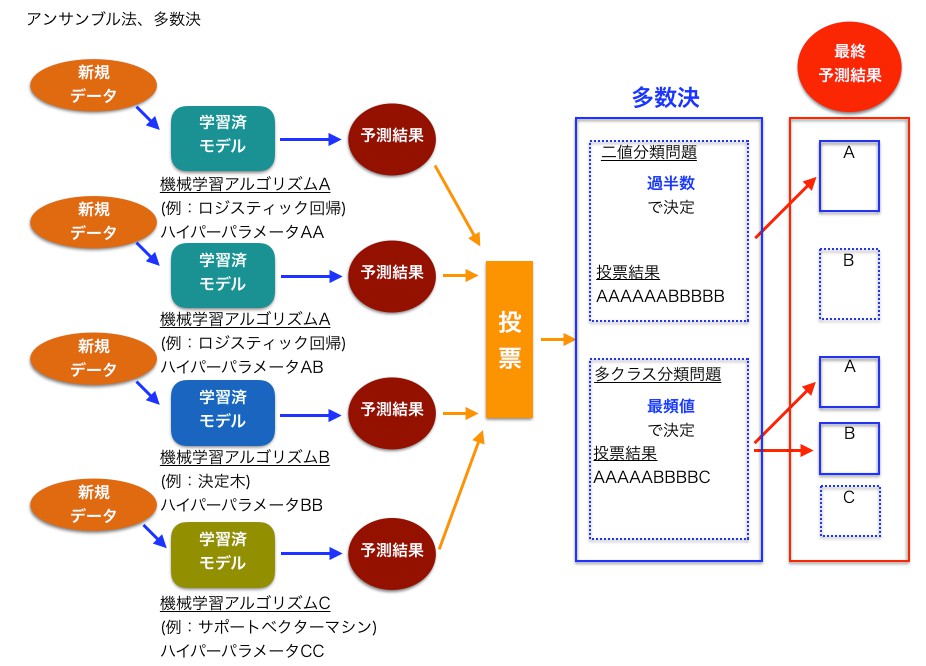
最も単純なアンサンブルは多数決です。複数のモデルに学習させた結果、多数決で分類を決定する手法です。
複数のモデルを使うことで過学習に陥りにくくなります。
今回のランダムフォレストもアンサンブルの一種で、複数の決定木を学習させて多数決をとる手法です。
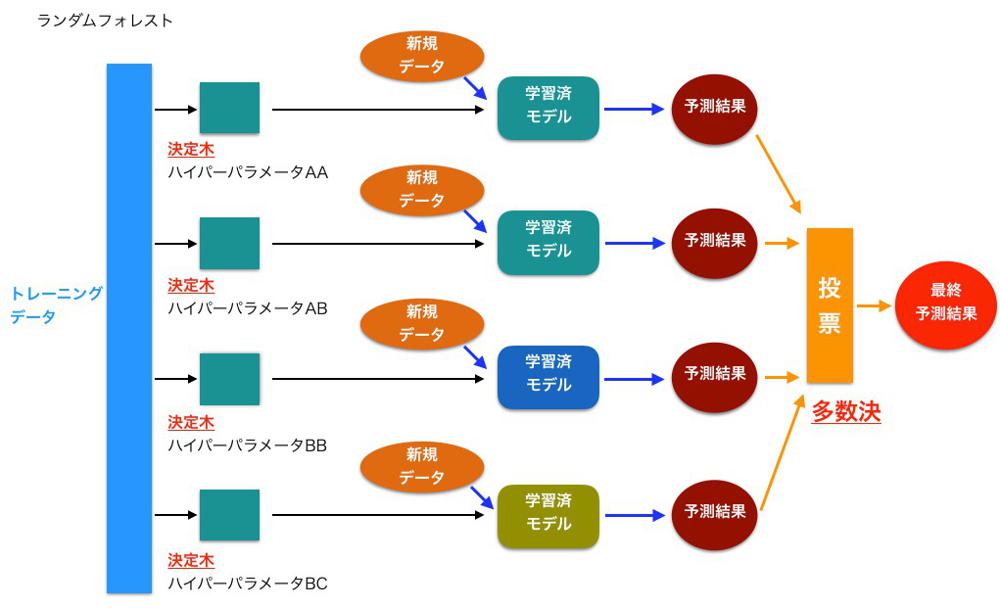
決定木の深さを単純に大きくすると過学習に陥りやすくなりますが、複数の決定木を学習させることで過学習を回避できます。
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def arange2(a, num):
"""numpy.ndarrayを最小と最大の間でnum+1分割する"""
amin, amax = a.min(), a.max()
return np.arange(amin, amax + 1e-8, (amax - amin) / num)
def plot_tree(clf, X, y, num=50, colors=('red', 'blue')):
"""
X.iloc[:, 0]とX.iloc[:, 1]の2次元で、yの0-1ラベルによる散布図と
予測(clf.predict)の等高線(contourf)を描画
"""
columns = X.columns
X, y = X.to_numpy(), y.to_numpy()
xx0, xx1 = np.meshgrid(arange2(X[:, 0], num), arange2(X[:, 1], num))
df = pd.DataFrame([xx0.ravel(), xx1.ravel()], index=columns).T
Z = clf.predict(df).reshape(xx0.shape)
plt.contourf(xx0, xx1, Z, alpha=0.4, cmap=ListedColormap(colors))
for i in range(2):
plt.scatter(X[y == i, 0], X[y == i, 1], alpha=0.8, c=colors[i])
plt.show()# データの読込
df = pd.read_csv('./input/wine.csv')
df.head(3)
# 特徴行列 X と目的変数 y へ分離
X = df.iloc[:, [1, 2]]
y = df.iloc[:, 11]from sklearn.model_selection import train_test_split
# トレーニング・テスト用に分割
(X_train, X_test,
y_train, y_test) = train_test_split(X, y, test_size=0.3, random_state=0)from sklearn.ensemble import RandomForestClassifier
# モデル作成
forest = RandomForestClassifier(n_estimators=8, max_depth=3, random_state=0)# 学習
forest.fit(X_train, y_train)RandomForestClassifier(max_depth=3, n_estimators=8, random_state=0)
# スコア算出
forest.score(X_test, y_test)0.7555555555555555
# 学習した領域のプロット
plot_tree(forest, X, y)
scikit-learnの RandomForestClassifier を使って分類しました。
プロットした領域を見ても、決定木のような軸に平行な分類がされていますし、過学習にも陥ってないことがわかります。
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=8, max_depth=3, random_state=0)
forest.fit(X, y)この RandomForestClassifier も他の分類器と同様に、 .fit(…) 、 .score(…) や .predict(…) メソッドが使えます。
パラメーターには決定木の数などを指定できます
n_estimators: 多数決させる決定木の数
max_depth: 1つ1つの決定木の最大の深さ
random_state: 乱数のシード値
他にも並列実行数 n_jobs など便利なパラメーターも指定できます。
全てのパラメーターの利用
# 前回のプログラムの読込
%run 1.ipynb
df.head()X = df.iloc[:, 0:11]
y = df.iloc[:, 11]
(X_train, X_test,
y_train, y_test) = train_test_split(X, y, test_size=0.3, random_state=0)forest = RandomForestClassifier(n_estimators=6, max_depth=3, random_state=0)
forest.fit(X_train, y_train)RandomForestClassifier(max_depth=3, n_estimators=6, random_state=0)
forest.score(X_test, y_test)0.7444444444444445

コメント