

これまでに2つのハイパーパラメーターが登場しました。
LogisticRegression の C
DecisionTreeClassifier の max_depth
クロスバリデーションを使って、最適なハイパーパラメーターを求めましょう(ハイパーパラメーターをチューニング)。
前回と同様に、最も結果の良い max_depth を求めます。
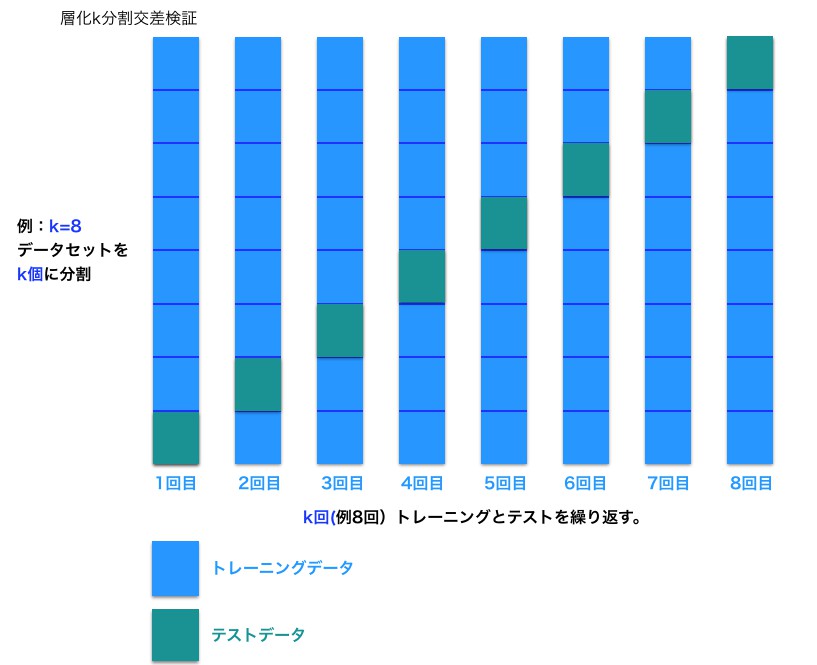
クロスバリデーションとは
今は一度「トレーニングデータで学習 => テストデータで判定」を実行していますが、何度か試してハイパーパラメーターを決めることが有用です。
何度か実行しますが、評価はテストデータのスコアの平均で判断することにします。
データをトレーニング・テスト用に分割しただけでは、評価は1回しかできませんが、N個に分割してN回評価できます。
そのための手法がクロスバリデーションと呼ばれるものです。
scikit-learnでは cross_validate 関数を使って簡単にクロスバリデーションできます。
scores = cross_validate(
estimator=clf, # 分類器を指定
X=X, # 特徴行列 X を指定
y=y, # 目的変数 y を指定
cv=8, # データを何分割にして検証するか指定
return_train_score=True # 結果にtrain_scoreを含めるか
)cross_validate は、内部では層化k分割交差検証という手法を使って偏りのないようにスコアを計算します。
cv には内部でデータを何分割してスコアを計算するかを指定できます。
cross_validate 関数は cv の数と同じ長さの numpy.array を返します。
arrayの各値が、1回ごとに計算したスコアの値になります。
このarrayから平均を計算することで、最終的なスコアを計算して性能評価ができます。
ハイパーパラメーターチューニングをしよう
max_depth を1から9まで変えて、cross_validate を実行します。
平均が一番良いハイパーパラメーター(max_depth)を選びます。
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
# データの読込
df = pd.read_csv('input/data14.csv')
# 特徴行列 X と目的変数 y へ分離
X = df[['x0', 'x1']]
y = df['y']# クロスバリデーション
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_validate
tree = DecisionTreeClassifier(max_depth=4, random_state=0)
result = cross_validate(
estimator=tree, X=X, y=y, cv=3, return_train_score=True)
result{'fit_time': array([0.00469899, 0.00275254, 0.00262737]),
'score_time': array([0.00173926, 0.00164056, 0.00158525]),
'test_score': array([0.71666667, 0.61666667, 0.63333333]),
'train_score': array([1. , 0.875 , 0.88333333])}
# 決定木のスコア確認(クロスバリデーション版)
def check_tree(X, y, max_depth, cv):
import numpy as np
tree = DecisionTreeClassifier(max_depth=max_depth, random_state=0)
result = cross_validate(
estimator=tree, X=X, y=y, cv=cv, return_train_score=True)
return tree, np.mean(result['train_score']), np.mean(result['test_score'])# モデルの複雑さとスコア
max_depths = [1, 2, 3, 4, 5, 6, 7, 8, 9]
score_trains = []
score_tests = []
for max_depth in max_depths:
_, score_train, score_test = check_tree(X, y, max_depth, cv=3)
print('max_depth', max_depth, 'train', score_train, 'test', score_test)
score_trains.append(score_train)
score_tests.append(score_test)max_depth 1 train 0.7305555555555556 test 0.5444444444444444
max_depth 2 train 0.8111111111111112 test 0.6166666666666667
max_depth 3 train 0.8777777777777778 test 0.6555555555555556
max_depth 4 train 0.9194444444444444 test 0.6555555555555556
max_depth 5 train 0.9305555555555555 test 0.7333333333333334
max_depth 6 train 0.9527777777777778 test 0.6944444444444443
max_depth 7 train 0.9722222222222223 test 0.7055555555555556
max_depth 8 train 0.9833333333333334 test 0.7055555555555556
max_depth 9 train 0.9944444444444445 test 0.7000000000000001# モデルの複雑さとスコア1のプロット
plt.xlabel('max_depth')
plt.plot(max_depths, score_trains, label='train')
plt.plot(max_depths, score_tests, label='test')
plt.legend();
# 最も当てはまったモデルのスコア
max(score_tests)0.7333333333333334
前回は max_depthが4のときに最良な結果だったので4を選びましたが、今回の結果から max_depth=5のほうが良いとわかりました。
クロスバリデーションによって、評価を増やすことにより、より信頼できる方法で分類器の性能評価ができています。
また、scikit-learnの cross_validate はCPUのコアごとに並列分散処理する機能も備えています。
cross_validateのスコアについて
cross_validate でscoring=None(デフォルト)の場合、第1引数(estimator)のスコア関数を使用します。
また、estimatorすなわち、DecisionTreeClassifierのスコア関数は、正解率です。
クロスバリデーションのテストのスコアだけで良い場合は、cross_validateではなく、cross_val_score が使えます。
from sklearn.model_selection import cross_val_score
cross_val_score(estimator=tree, X=X, y=y, cv=3)array([ 0.71666667, 0.61666667, 0.63333333])
コメント