

cumcount()
cumcount() はDataFrameにはなく、DataFrameGroupByだけで使えるメソッドです。グループごとに、データに対して通し番号をふりたい時に使います。たとえば、以下のようなケースです。
- 複数ユーザーの購入履歴のログで、ユーザーごとに何回目の購入データかわかるように識別子をふる
- 複数クラスの試験結果のデータで、クラスごとに生徒に対して一意な識別子をふる
次のように記述して使います。
# 指定した列名でグループ化
grouped = df.groupby(列名)
# グループごとに0始まりの通し番号をふる
grouped.cumcount()デフォルトでは、上の行から順に通し番号をふります。下の行から通し番号をふりたい場合は、引数ascendingでFalseを指定します。
DataFrameGroupByのrank()は列ごとに値を計算するため結果がDataFrameになりますが、cumcount()は行の並び順で値が決まります。つまり、列の値は無関係なので、結果はSeriesになります。
具体的な例を見てみましょう。次のような試験結果と学習時間のデータについて考えます。
生徒ID | クラス | 点数 | 学習時間(分) |
|---|---|---|---|
| ST001 | 1-A | 60 | 232 |
| ST002 | 1-A | 87 | 345 |
| ST003 | 1-B | 66 | 180 |
| ST004 | 1-A | 72 | 22 |
| ST005 | 1-B | 74 | 120 |
| ST006 | 1-B | 58 | 215 |
クラスごとに、各データに0始まりの通し番号をふってみましょう。
# 列「クラス」でグループ化
grouped = df.groupby("クラス")
# グループごとに0始まりの通し番号をふる
grouped.cumcount()実行結果:
生徒ID
ST001 0
ST002 1
ST003 0
ST004 2
ST005 1
ST006 2
dtype: int64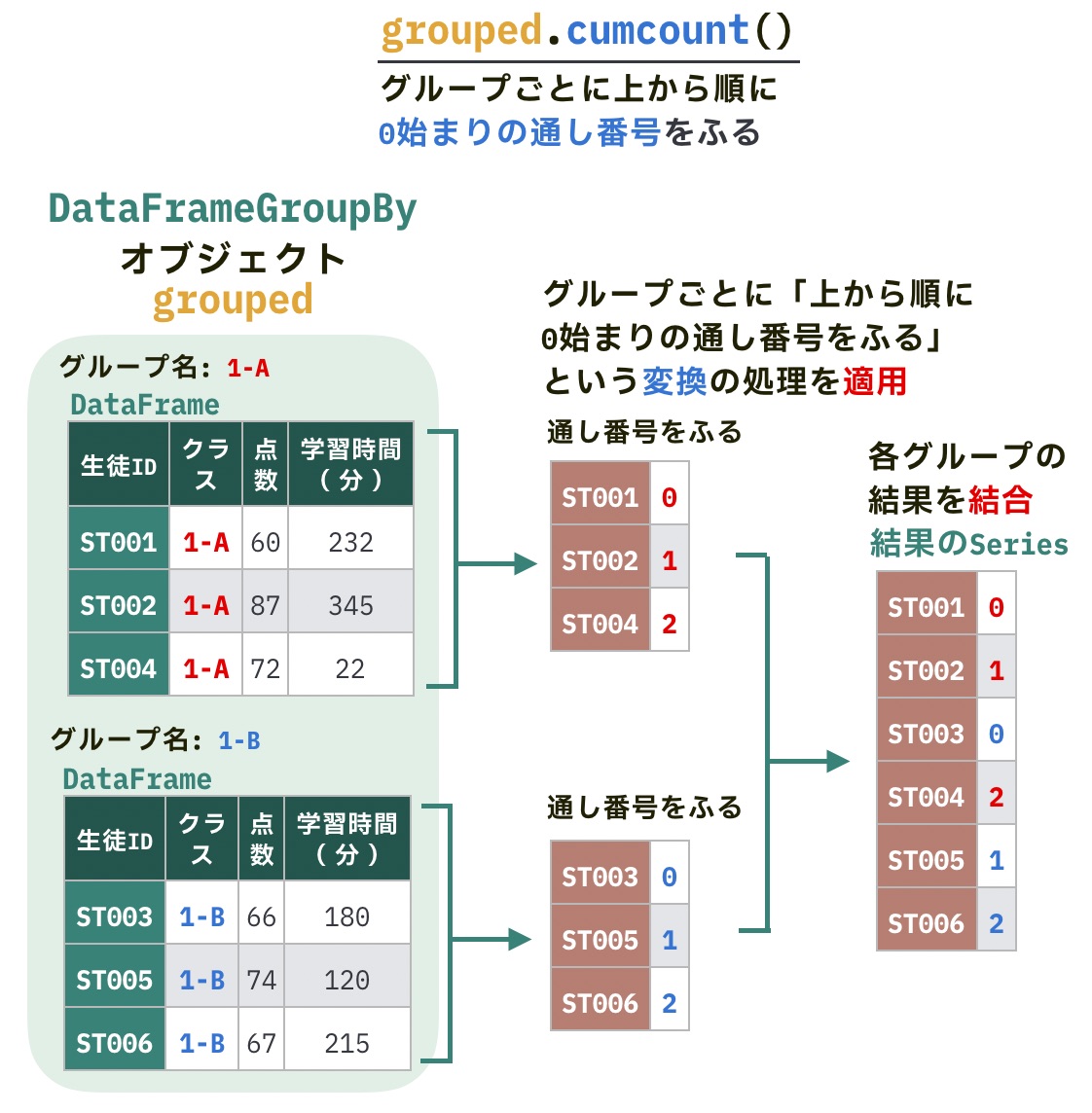
各グループごとに、上から順に通し番号がふられていることがわかります。
たとえば、クラス1-Aのデータ(ST001、ST002、ST004)は、行の並び順にしたがって生徒ST001が0、 生徒ST002が1、生徒ST004が2になっています。
演習
import pandas as pd
# 試験結果のデータを読み込み
df = pd.read_csv("dataset/score_study_time.csv", index_col="生徒ID")
# 先頭5行を確認
df.head()
| クラス | 点数 | 学習時間(分) | |
|---|---|---|---|
| 生徒ID | |||
| ST001 | 1-A | 48.0 | 226 |
| ST002 | 1-A | 0.0 | 24 |
| ST003 | 1-B | 80.0 | 271 |
| ST004 | 1-A | NaN | 45 |
| ST005 | 1-A | 68.0 | 271 |
今回はクラスごとに通し番号をふるので、groupby()を使ってクラスごとにグループ化します。
# 列「クラス」でグループ化
grouped = df.groupby("クラス")
各クラスの上の行から順に、0始まりの通し番号を割り当てましょう。
これは、cumcount()を使って実現できます。rank()は列ごとに計算されるので結果はDataFrameでしたが、cumcount()は列の値は関係ないため、結果はSeriesの形で得られます。
# グループ内で上から順に通し番号をつける cumcount_df = grouped.cumcount() cumcount_df
生徒ID ST001 0 ST002 1 ST003 0 ST004 2 ST005 3 ST006 1 ST007 4 ST008 2 ST009 3 ST010 4 ST011 5 ST012 6 ST013 5 ST014 6 ST015 7 ST016 8 ST017 7 ST018 9 ST019 8 ST020 9 dtype: int64
実行結果を、新しい列として元のDataFrameに追加しましょう。In [4]:
# グループ内での通し番号を新しい列として追加する df["グループ内ID"] = cumcount_df # 結果の先頭5行を確認 df.head()
| クラス | 点数 | 学習時間(分) | グループ内ID | |
|---|---|---|---|---|
| 生徒ID | ||||
| ST001 | 1-A | 48.0 | 226 | 0 |
| ST002 | 1-A | 0.0 | 24 | 1 |
| ST003 | 1-B | 80.0 | 271 | 0 |
| ST004 | 1-A | NaN | 45 | 2 |
| ST005 | 1-A | 68.0 | 271 | 3 |
確認のため、クラスが1-Aのデータの結果を見てみましょう。クラス1-Aのデータの中で上の行から順に0、1、2……と通し番号が割り振られていることがわかります。In [5]:
# 1-Aのデータだけを確認する df[df["クラス"] == "1-A"]
| クラス | 点数 | 学習時間(分) | グループ内ID | |
|---|---|---|---|---|
| 生徒ID | ||||
| ST001 | 1-A | 48.0 | 226 | 0 |
| ST002 | 1-A | 0.0 | 24 | 1 |
| ST004 | 1-A | NaN | 45 | 2 |
| ST005 | 1-A | 68.0 | 271 | 3 |
| ST007 | 1-A | 49.0 | 236 | 4 |
| ST011 | 1-A | 98.0 | 381 | 5 |
| ST012 | 1-A | 84.0 | 286 | 6 |
| ST017 | 1-A | 81.0 | 355 | 7 |
| ST019 | 1-A | 78.0 | 326 | 8 |
| ST020 | 1-A | 90.0 | 301 | 9 |
同様に、クラス1-Bのデータも確認してみましょう。こちらも、グループ内の上の行から順に0始まりの通し番号が付与されていることがわかります。このように、DataFrameGroupByオブジェクトのcumcount()ではグループ単位で変換処理が適用されます。In [6]:
# 1-Bのデータだけを確認する df[df["クラス"] == "1-B"]
| クラス | 点数 | 学習時間(分) | グループ内ID | |
|---|---|---|---|---|
| 生徒ID | ||||
| ST003 | 1-B | 80.0 | 271 | 0 |
| ST006 | 1-B | 58.0 | 215 | 1 |
| ST008 | 1-B | 79.0 | 334 | 2 |
| ST009 | 1-B | 75.0 | 256 | 3 |
| ST010 | 1-B | NaN | 229 | 4 |
| ST013 | 1-B | 58.0 | 192 | 5 |
| ST014 | 1-B | 83.0 | 286 | 6 |
| ST015 | 1-B | 62.0 | 220 | 7 |
| ST016 | 1-B | 69.0 | 222 | 8 |
| ST018 | 1-B | NaN | 224 | 9 |

コメント