

次のようにDataFrameのgroupby()メソッドを使うと、指定した列の値に応じてデータがグループ化されます。
# 指定した列でグループ化
df.groupby(列名)DataFrameをグループ化した結果(df.groupby(列名)の実行結果)は、 DataFrameGroupBy型のオブジェクトになります。
DataFrameGroupByオブジェクトにはグループに関する情報が含まれており、集約・変換・抽出のためのメソッドと組み合わせることで、グループごとの処理を適用できます。
具体的に、簡単な集約の例を見てみましょう。次のような試験結果のデータがあるとします。1行に1生徒の成績が格納されており、各生徒は1-A・1-Bのいずれかのクラスに属しています。インデックスには、生徒IDが設定されています。
このデータを使って、各クラスの点数の平均 と 各クラスの学習時間(分)の平均 を計算してみましょう。
生徒ID | クラス | 点数 | 学習時間(分) |
|---|---|---|---|
| ST001 | 1-A | 60 | 232 |
| ST002 | 1-A | 87 | 345 |
| ST003 | 1-B | 66 | 180 |
| ST004 | 1-A | 72 | 22 |
| ST005 | 1-B | 74 | 120 |
| ST006 | 1-B | 58 | 215 |
今回は列クラスがグループ化の基準なので、groupby()の引数にはクラスを指定します。
# 列「クラス」でグループ化
grouped = df.groupby("クラス")groupedは、DataFrameGroupBy型のオブジェクトです。
DataFrameGroupByオブジェクトにはグループに関する情報が含まれており、各グループは次のように グループ名(キー) と データ(DataFrame) で構成されています。
前問で説明した 分割・適用・結合の3ステップに当てはめると、groupby()の処理は「分割」のステップに相当します。
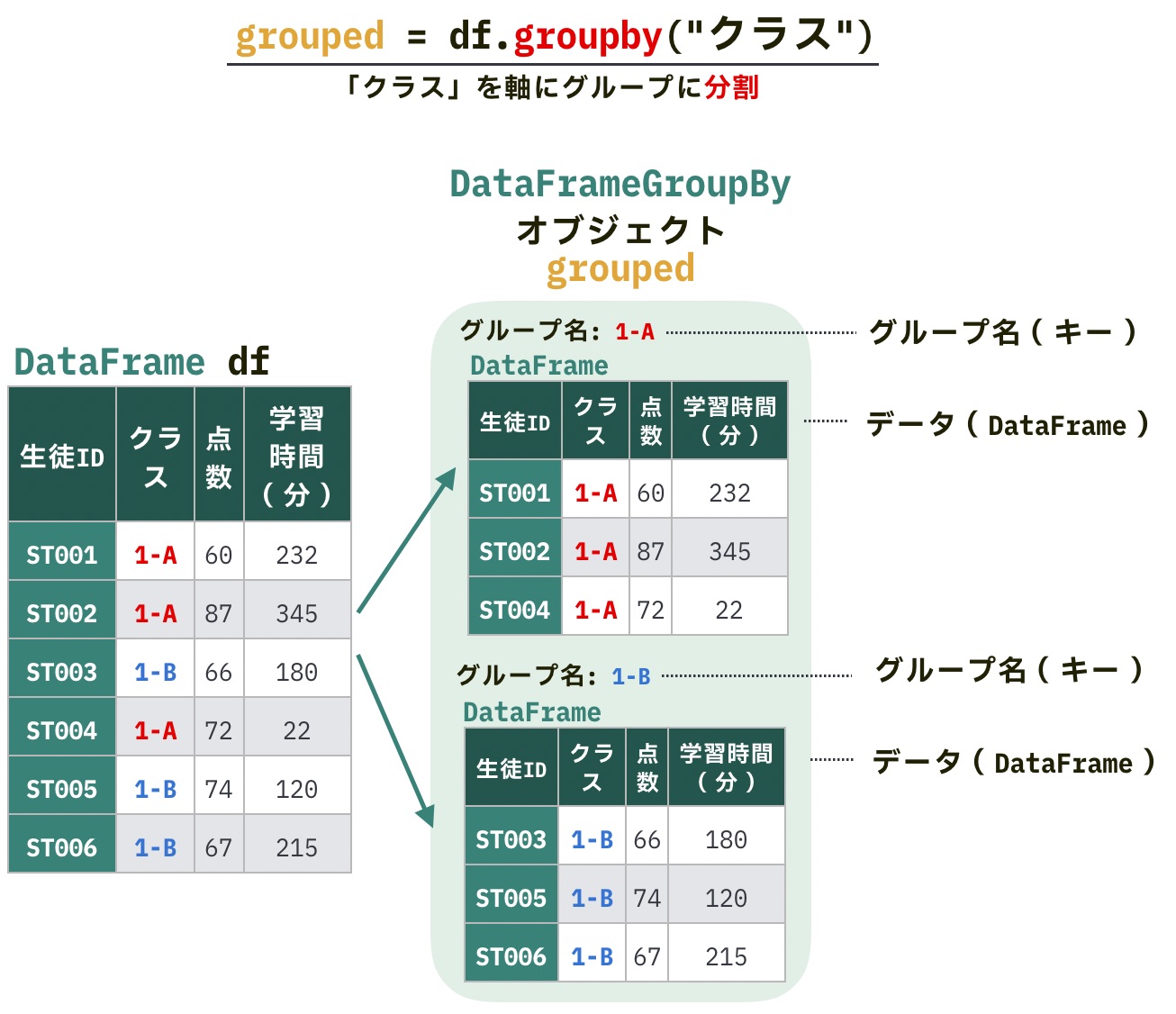
DataFrameGroupByオブジェクトはそのままでは中身を確認できませんが、groups属性を使うと、グループ化された情報を辞書形式で確認できます。
# グループ化された情報を確認
grouped.groups{'1-A': ['ST001', 'ST002', 'ST004'], '1-B': ['ST003', 'ST005', 'ST006']}キーがグループ名、値が「そのグループに属する行のインデックスの一覧」です。今回は生徒IDがインデックスなので、各クラスに属する生徒IDの一覧を確認できることがわかります。
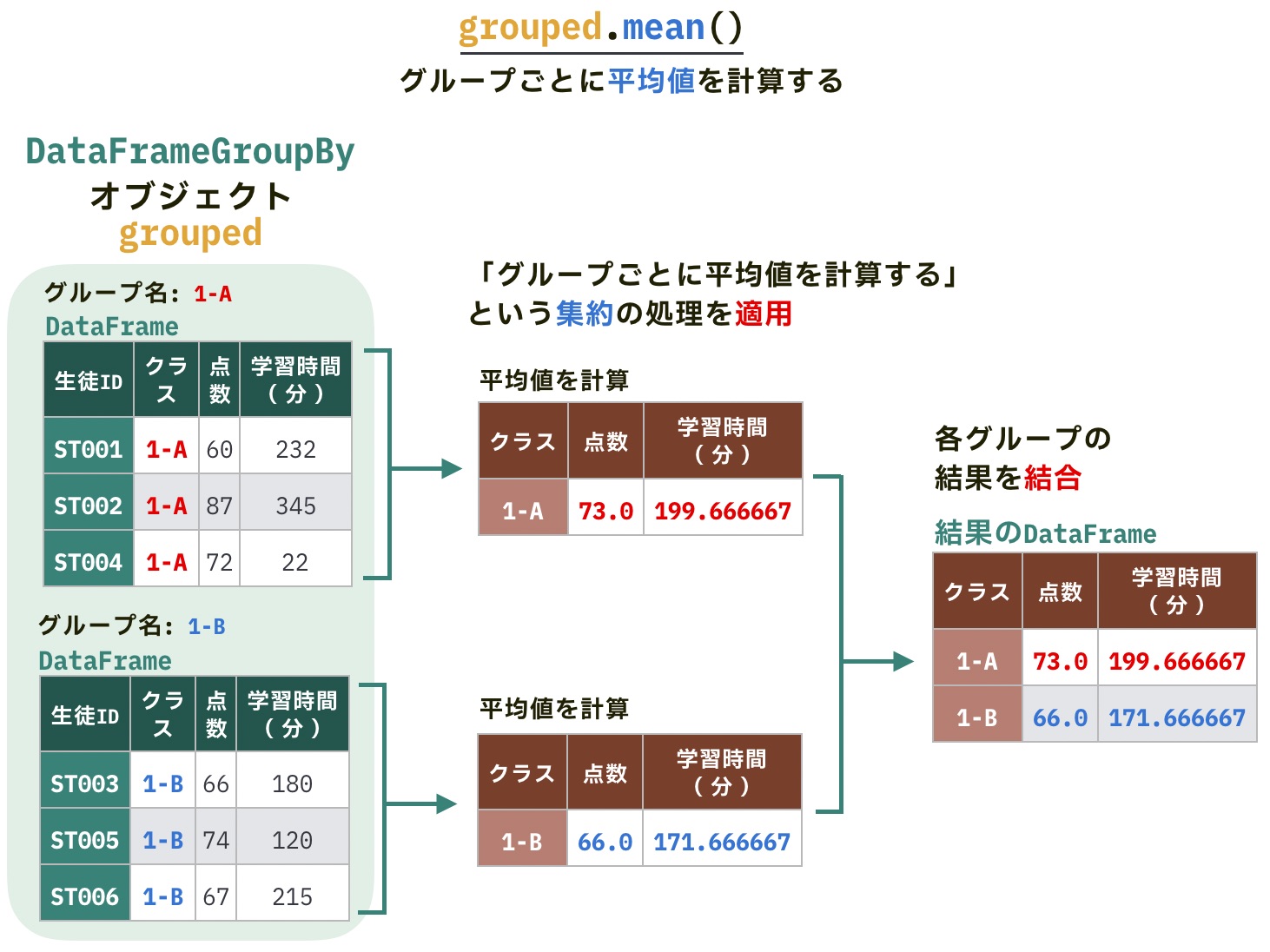
DataFrameGroupByオブジェクトのmean()を使うと、グループごとに各列の平均を計算します。
# グループごとに平均を計算
grouped.mean()| クラス | 点数 | 学習時間(分) |
|---|---|---|
| 1-A | 73.0 | 199.666667 |
| 1-B | 66.0 | 171.666667 |
検算した結果と比較すると、意図通り各クラスの平均が計算されていることがわかります。
列点数の場合:
- 1-A: (60 + 87 + 72) / 3 = 73.0
- 1-B: (66 + 74 + 58) / 3 = 66.0
前問で説明した分割・適用・結合の3ステップに当てはめると、mean()の処理は「適用」と「結合」のステップに相当します。
この他にも、最大値を求めるmax()や最小値を求めるmin()など、DataFrameGroupByは集約のためのさまざまなメソッドを持っています。
先ほどの例では、DataFrameGroupByオブジェクトとmean()を組み合わせて、すべての列について各グループの平均を計算しました。
すべての列ではなく、特定の列だけをグループごとに集約したい場合は、SeriesGroupByオブジェクトが使えます。
DataFrameでは、df[列名]のように[]で列名を指定することで特定の列のSeriesを取得できました。同様に、DataFrameGroupByでも、grouped[列名]とすることで特定の列のSeriesGroupByオブジェクトを取得できます。
一部異なる点はありますが、SeriesGroupByではDataFrameGroupByと同じように集約メソッドなどが使えます。
# 指定した列でグループ化
grouped = df.groupby(列名1)
# 指定した列について、グループごとに集約
# grouped[列名2]の部分がSeriesGroupByオブジェクト
grouped[列名2].集約メソッド()たとえば、今回のデータで列点数だけクラスごとに平均を計算したい場合、次のように書きます。
# 列「クラス」でグループ化
grouped = df.groupby("クラス")
# グループごとに列「点数」の平均を計算
grouped["点数"].mean()クラス
1-A 73.0
1-B 66.0
Name: 点数, dtype: float64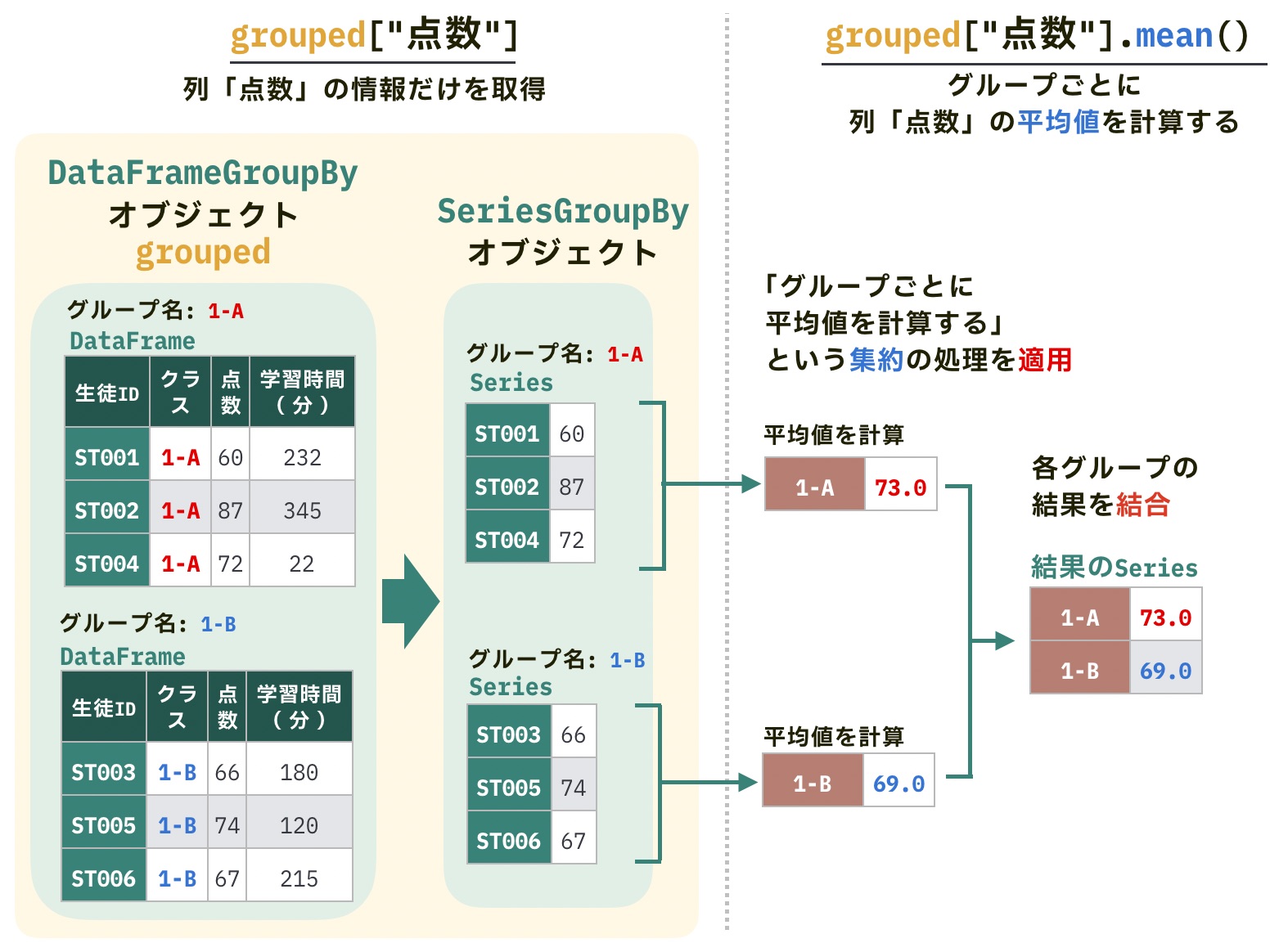
groupbyオブジェクトの性質
get_group
df.groupby('city').get_group('osaka')city | food | price | quantity | |
|---|---|---|---|---|
| 0 | osaka | apple | 100 | 1 |
| 1 | osaka | orange | 200 | 2 |
| 2 | osaka | banana | 250 | 3 |
| 3 | osaka | banana | 300 | 4 |
.groups
df.groupby('city').groups{'osaka': Int64Index([0, 1, 2, 3], dtype='int64'),
'tokyo': Int64Index([4, 5, 6], dtype='int64')}.size()
df.groupby('city').size()city
osaka 4
tokyo 3
dtype: int64df.groupby('city').size()['osaka']4
コメント