

勉強時間を記録するアプリケーションのログについて考えてみます。
「勉強開始」「勉強終了」「一時停止」「再開」のイベント種別と、イベントが発生した日時が記録されています。
| 日時 | イベント | |
|---|---|---|
| 0 | 2022/1/1 13:00 | 勉強開始 |
| 1 | 2022/1/1 13:40 | 勉強終了 |
| 2 | 2022/1/1 14:50 | 勉強開始 |
| 3 | 2022/1/1 15:00 | 一時停止 |
| 4 | 2022/1/1 15:10 | 再開 |
| 5 | 2022/1/1 16:00 | 勉強終了 |
| 6 | 2022/1/2 10:00 | 勉強開始 |
| 7 | 2022/1/2 10:30 | 勉強終了 |
上記のデータを、次のような形式に変換したいです。
- (1)「勉強開始」と「勉強終了」の組にして1行にする
- (2)「勉強開始」と「勉強終了」の間に「一時停止」と「再開」があった場合、「一時停止」から「再開」までの時間を休憩時間として扱い、何分休憩したか持つ
- (3)「勉強時間」は、休憩時間を考慮して
勉強終了日時 - 勉強開始日時 - 休憩時間で計算する
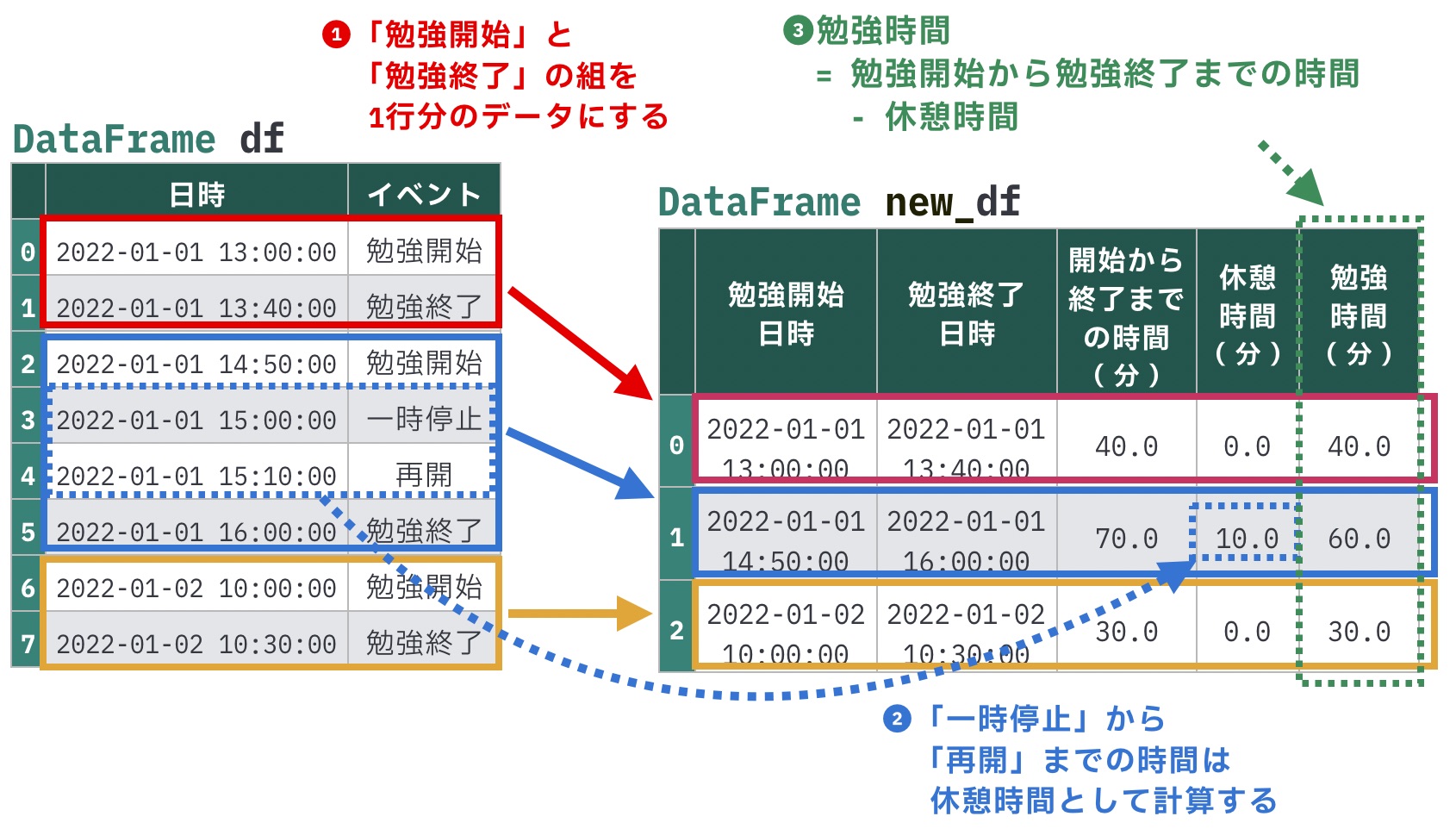
新しいnew_dfの内容
| 勉強開始日時 | 勉強終了日時 | 開始から終了までの時間(分) | 休憩時間(分) | 勉強時間(分) | |
|---|---|---|---|---|---|
| 0 | 2022-01-01 13:00:00 | 2022-01-01 13:40:00 | 40.0 | 0.0 | 40.0 |
| 1 | 2022-01-01 14:50:00 | 2022-01-01 16:00:00 | 70.0 | 10.0 | 60.0 |
| 2 | 2022-01-02 10:00:00 | 2022-01-02 10:30:00 | 30.0 | 0.0 | 30.0 |
一連の行の流れを見るので、単純にapply()などで実装するのは難しそうです。
for文で1行ずつ処理していく場合、次のような流れになります。少し長くなりますが、ここでは処理の詳細よりも、「apply()だけでは難しそうだ」「上から1行ずつデータを見て処理する必要がありそうだ」という点だけわかれば大丈夫です。
- (1)変換後の
new_dfの行データを格納するリストを用意する - (2)DataFrameのデータを上から1行ずつ見ていく
- a. イベントが「勉強開始」だった場合、列
日時の値を勉強開始日時として覚えておく - b. イベントが「一時停止」だった場合、列
日時の値を休憩開始日時として覚えておく - c. イベントが「再開」だった場合、列
日時の値を休憩終了日時とし、前回までのループで覚えておいた休憩開始日時との差を休憩時間(分)として計算する - d. イベントが「勉強終了」だった場合
- 列
日時の値を勉強終了日時とし、前回までのループで覚えておいた勉強開始時刻との差を開始から終了までの時間(分)とする。 開始から終了までの時間(分)と前回までのループで覚えておいた休憩時間(分)を使って、new_df用の新しい行データを作る休憩時間(分)をリセットする
- 列
- a. イベントが「勉強開始」だった場合、列
- (3)すべての行について処理が完了したら、新しい行データのリストでDataFrame(
new_df)を作る - (4)列
開始から終了までの時間(分)から列休憩時間(分)を引いて列勉強時間(分)を計算する
このような1行ずつ逐次的にデータを処理していく場合、itertuples()が便利です。
itertuples()を使うと、行データを取得するイテレータが得られます。そのためfor文と組み合わせることで、1行ずつデータを取得できます。
シンプルな例として、まずは1行ずつ表示してみましょう。
for row in df.itertuples():
# 行データを表示
print(row)Pandas(Index=0, 日時='2022/1/1 13:00', 状態='勉強開始')
Pandas(Index=1, 日時='2022/1/1 13:40', 状態='勉強終了')
...略...
Pandas(Index=6, 日時='2022/1/2 10:00', 状態='勉強開始')
Pandas(Index=7, 日時='2022/1/2 10:30', 状態='勉強終了')itertuples()を使うと、各行のデータが 名前付きタプル( namedtuple ) で得られます。
名前付きタプルとはタプルに似たデータ型で、各要素に名前を付けられる点が特徴です。通常のタプルではインデックス番号で要素にアクセスしますが、名前付きタプルでは要素の名前でもアクセス可能です。
今回の場合、各行はPandasと名づけられた名前付きタプルで取得されています。各要素には、Index、日時、状態という名前が付けらており、元のDataFrameのインデックスと列に対応しています。
列日時のデータには、row.日時でアクセスできます。
for row in df.itertuples():
print(row.日時)2022-01-01 13:00:00
2022-01-01 13:40:00
...略...
2022-01-02 10:00:00
2022-01-02 10:30:00シンプルな例を通して、1行ずつデータを取得できることを確認できました。
演習
import pandas as pd
# イベントログデータの読み込み
# 列「日時」は日付時刻型として読み込む
df = pd.read_csv("dataset/event_log.csv", parse_dates=["日時"])
df| 日時 | イベント | |
|---|---|---|
| 0 | 2022-01-01 13:00:00 | 勉強開始 |
| 1 | 2022-01-01 13:40:00 | 勉強終了 |
| 2 | 2022-01-01 14:50:00 | 勉強開始 |
| 3 | 2022-01-01 15:00:00 | 一時停止 |
| 4 | 2022-01-01 15:10:00 | 再開 |
| 5 | 2022-01-01 16:00:00 | 勉強終了 |
| 6 | 2022-01-02 10:00:00 | 勉強開始 |
| 7 | 2022-01-02 10:30:00 | 勉強終了 |
まずは、シンプルな例でitertuples()の挙動を確認してみましょう。
次のコードを実行すると、for文とitertuples()を組み合わせて、行を1つずつ表示します。
for row in df.itertuples():
# 行データを表示
print(row)Pandas(Index=0, 日時=Timestamp('2022-01-01 13:00:00'), イベント='勉強開始')
Pandas(Index=1, 日時=Timestamp('2022-01-01 13:40:00'), イベント='勉強終了')
Pandas(Index=2, 日時=Timestamp('2022-01-01 14:50:00'), イベント='勉強開始')
Pandas(Index=3, 日時=Timestamp('2022-01-01 15:00:00'), イベント='一時停止')
Pandas(Index=4, 日時=Timestamp('2022-01-01 15:10:00'), イベント='再開')
Pandas(Index=5, 日時=Timestamp('2022-01-01 16:00:00'), イベント='勉強終了')
Pandas(Index=6, 日時=Timestamp('2022-01-02 10:00:00'), イベント='勉強開始')
Pandas(Index=7, 日時=Timestamp('2022-01-02 10:30:00'), イベント='勉強終了')itertuples()では、名前付きタプルで1行分のデータを取得します。名前付きタプルは変数.要素名で各要素を参照できます。for文の中で各行の列日時と列イベントの値を表示してみましょう。
for row in df.itertuples():
# 行データの日時とイベントを表示
print(row.日時, row.イベント)2022-01-01 13:00:00 勉強開始
2022-01-01 13:40:00 勉強終了
2022-01-01 14:50:00 勉強開始
2022-01-01 15:00:00 一時停止
2022-01-01 15:10:00 再開
2022-01-01 16:00:00 勉強終了
2022-01-02 10:00:00 勉強開始
2022-01-02 10:30:00 勉強終了itertuples()を使うと、for文の中で1行ずつ処理できることがわかりました。
本文で紹介した例を、実際にitertuples()を使って実装してみます。ここから少しコードが長くなりますが、実装の詳細より「itertuples()を使うとfor文を使ってデータ処理の幅が広がる」という点がイメージできれば大丈夫です。
次のコードでは、itertuples()を使って行を順に処理していき、列イベントを元に “勉強開始”から次の”勉強終了”までの時間 を計算しています(start_end_diff)。
計算結果は、”勉強開始”の行の日時(start_time)と”勉強開始”の行の日時(end_time)とともに 新しい行のデータ としてリスト(new_rows)に追加します。
# 新しい行を格納するリスト
new_rows = []
for row in df.itertuples():
if row.イベント == "勉強開始":
# 後で勉強時間を計算できるように、勉強開始時の日時を覚えておく
start_time = row.日時
elif row.イベント == "勉強終了":
end_time = row.日時
# 「勉強開始」から「勉強終了」までの時間(分)
start_end_diff = (end_time - start_time).seconds / 60
# 新しい行となるデータを作成
new_row = {
"勉強開始日時": start_time,
"勉強終了日時": end_time,
"開始から終了までの時間(分)": start_end_diff,
}
new_rows.append(new_row)
else:
# 「一時停止」「再開」は現段階ではスキップ
continue
# 新しい行のリストを確認
new_rows[{'勉強開始日時': Timestamp('2022-01-01 13:00:00'),
'勉強終了日時': Timestamp('2022-01-01 13:40:00'),
'開始から終了までの時間(分)': 40.0},
{'勉強開始日時': Timestamp('2022-01-01 14:50:00'),
'勉強終了日時': Timestamp('2022-01-01 16:00:00'),
'開始から終了までの時間(分)': 70.0},
{'勉強開始日時': Timestamp('2022-01-02 10:00:00'),
'勉強終了日時': Timestamp('2022-01-02 10:30:00'),
'開始から終了までの時間(分)': 30.0}]新しい行のリストをDataFrameに変換して確認してみましょう。意図通り勉強開始と勉強終了のイベントの組が1行となった形式に変換されています。
# 新しい行のリストをDataFrameに変換
pd.DataFrame(new_rows)| 勉強開始日時 | 勉強終了日時 | 開始から終了までの時間(分) | |
|---|---|---|---|
| 0 | 2022-01-01 13:00:00 | 2022-01-01 13:40:00 | 40.0 |
| 1 | 2022-01-01 14:50:00 | 2022-01-01 16:00:00 | 70.0 |
| 2 | 2022-01-02 10:00:00 | 2022-01-02 10:30:00 | 30.0 |
次に、休憩時間を計算してみましょう。
先ほどのコードから変わったのは、【1】〜【5】の★の部分です。まず、休憩時間を計算するための変数break_timeを用意しています(【1】)。for文の中にイベントが”一時停止”だったときと”再開”だったときの条件分岐を追加することで 「勉強開始」から「勉強終了」までの間に何分の休憩時間があったか を計算しています(【2】【3】)。一連の行の並び方が重要になるので、このような処理は比較的itertuples()が向いています。計算した休憩時間は、新しい行のデータに追加しています(【4】)。最後に、勉強終了時には休憩時間をリセットするのを忘れないようにしましょう(【5】)。
# 新しい行を格納するリスト
new_rows = []
# ★【1】休憩時間を管理するための変数
break_time = 0 # 休憩時間(分)
for row in df.itertuples():
if row.イベント == "一時停止": # ★【2】一時停止(休憩開始)の処理
start_time_break = row.日時
elif row.イベント == "再開": # ★【3】再開(休憩終了)の処理
end_time_break = row.日時
# 休憩時間を加算(時間差を秒単位から分単位に変換)
break_time += (end_time_break - start_time_break).seconds / 60
elif row.イベント == "勉強開始":
start_time = row.日時
elif row.イベント == "勉強終了":
end_time = row.日時
# 「勉強開始」から「勉強終了」までの時間(分)
start_end_diff = (end_time - start_time).seconds / 60
# 新しい行を作成
# ★【4】休憩時間のデータを追加
new_row = {
"勉強開始日時": start_time,
"勉強終了日時": end_time,
"開始から終了までの時間(分)": start_end_diff,
"休憩時間(分)": break_time,
}
new_rows.append(new_row)
break_time = 0 # ★【5】 休憩時間をリセット
new_rows[{'勉強開始日時': Timestamp('2022-01-01 13:00:00'),
'勉強終了日時': Timestamp('2022-01-01 13:40:00'),
'開始から終了までの時間(分)': 40.0,
'休憩時間(分)': 0},
{'勉強開始日時': Timestamp('2022-01-01 14:50:00'),
'勉強終了日時': Timestamp('2022-01-01 16:00:00'),
'開始から終了までの時間(分)': 70.0,
'休憩時間(分)': 10.0},
{'勉強開始日時': Timestamp('2022-01-02 10:00:00'),
'勉強終了日時': Timestamp('2022-01-02 10:30:00'),
'開始から終了までの時間(分)': 30.0,
'休憩時間(分)': 0}]新しい行のリストをDataFrameに変換して確認してみましょう。意図通り、2行目の列休憩時間(分)にこの期間中に発生した休憩時間が格納されていることがわかります。
# 行のリストをDataFrameに変換
new_df = pd.DataFrame(new_rows)
new_df勉強開始日時 | 勉強終了日時 | 開始から終了までの時間(分) | 休憩時間(分) | |
|---|---|---|---|---|
| 0 | 2022-01-01 13:00:00 | 2022-01-01 13:40:00 | 40.0 | 0.0 |
| 1 | 2022-01-01 14:50:00 | 2022-01-01 16:00:00 | 70.0 | 10.0 |
| 2 | 2022-01-02 10:00:00 | 2022-01-02 10:30:00 | 30.0 | 0.0 |
最後に、休憩時間を考慮した勉強時間を計算します。
# 勉強時間を計算して新しい列を追加
new_df["勉強時間(分)"] = new_df["開始から終了までの時間(分)"] - new_df["休憩時間(分)"]
new_df| 勉強開始日時 | 勉強終了日時 | 開始から終了までの時間(分) | 休憩時間(分) | 勉強時間(分) | |
|---|---|---|---|---|---|
| 0 | 2022-01-01 13:00:00 | 2022-01-01 13:40:00 | 40.0 | 0.0 | 40.0 |
| 1 | 2022-01-01 14:50:00 | 2022-01-01 16:00:00 | 70.0 | 10.0 | 60.0 |
| 2 | 2022-01-02 10:00:00 | 2022-01-02 10:30:00 | 30.0 | 0.0 | 30.0 |
演習②
import pandas as pd
# 教材情報の読み込み
df = pd.read_csv("dataset/contents.csv")
df| 教材ID | 教材名 | |
|---|---|---|
| 0 | P001 | はじめてのプログラミング |
| 1 | P002 | pythonはじめの一歩 |
| 2 | D001 | pythonデータ処理初級 |
| 3 | D002 | pythonデータ処理中級 |
| 4 | D003 | pythonデータ処理実践 |
| 5 | W002 | Django初級 |
| 6 | W003 | Django中級 |
今回の処理は本来strアクセサを使って1行で書ける内容ですが、あえてitertuples()を使う場合、1行ずつループの中で教材名の置換処理を行う流れになります。
まずfor 行データ in df.itertuples():のように書いて、行データを1行ずつループで取得します。
次に、ループ処理の中で各行の教材名の置換処理を行います。
行データは名前付きタプルとして取得できるので、行データ.列名のようにして各列の値を参照できます。
今回は列教材名の値を使ってデータ処理を行いたいので、row.教材名を参照して置換します。
置換後のデータはリスト(after_list)に格納して、後で新しい列として使えるようにします。
# 変換後の値を格納するリスト(新しい列になる)
after_list = []
for row in df.itertuples():
# 列「教材名」内の"python"を"Python"に置換する
after = row.教材名.replace("python", "Python")
after_list.append(after)
after_list['はじめてのプログラミング',
'Pythonはじめの一歩',
'Pythonデータ処理初級',
'Pythonデータ処理中級',
'Pythonデータ処理実践',
'Django初級',
'Django中級']最後に、置換後のデータが格納されたafter_listを列教材名_変換後として追加します。df[新しい列名] = リストとすることで新しい列を作成できます。
# 変換後の値のリストを新しい列として追加
df["教材名_変換後"] = after_list
df| 教材ID | 教材名 | 教材名_変換後 | |
|---|---|---|---|
| 0 | P001 | はじめてのプログラミング | はじめてのプログラミング |
| 1 | P002 | pythonはじめの一歩 | Pythonはじめの一歩 |
| 2 | D001 | pythonデータ処理初級 | Pythonデータ処理初級 |
| 3 | D002 | pythonデータ処理中級 | Pythonデータ処理中級 |
| 4 | D003 | pythonデータ処理実践 | Pythonデータ処理実践 |
| 5 | W002 | Django初級 | Django初級 |
| 6 | W003 | Django中級 | Django中級 |

コメント