

変数result_srの作成:
各科目の列(国語、 数学 、理科、社会)について 「勉強時間の合計 / 勉強した日数」 を計算して、結果のSeriesを変数result_srに格納してください。
import pandas as pd
# 科目ごとの勉強時間データの読み込み
df = pd.read_csv("dataset/exercise_study_log.csv", index_col="日付")
df| 国語 | 数学 | 理科 | 社会 | |
|---|---|---|---|---|
| 日付 | ||||
| 2022/1/1 | 14 | 32 | 45 | 0 |
| 2022/1/2 | 0 | 150 | 13 | 0 |
| 2022/1/3 | 20 | 180 | 30 | 15 |
| 2022/1/4 | 10 | 28 | 0 | 0 |
| 2022/1/5 | 30 | 45 | 45 | 29 |
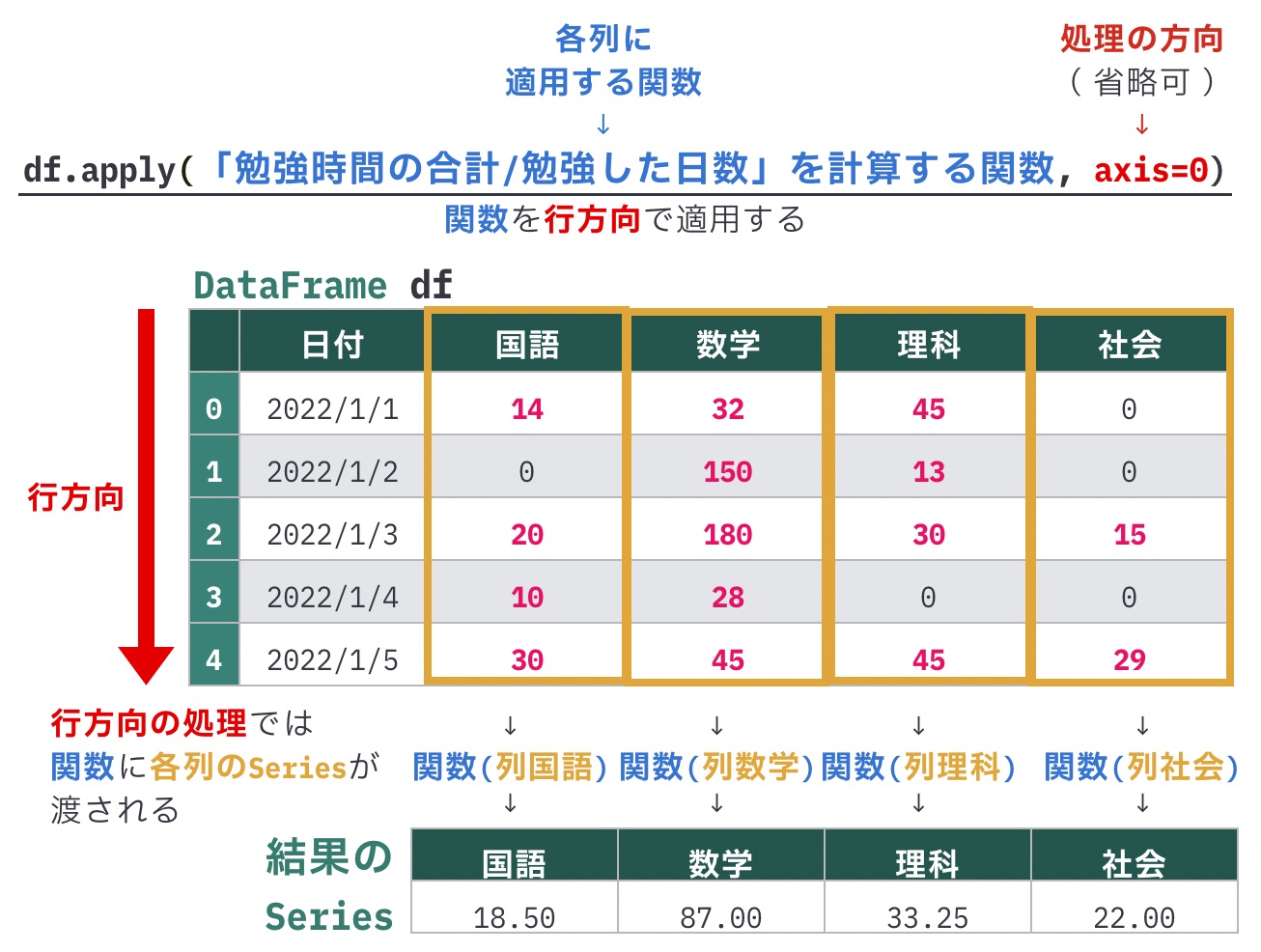
「勉強時間の合計 / 勉強した日数」を計算する関数では、引数で各列に相当するSeriesを受け取って、戻り値で計算結果を返すようにします。
def calc_mean(column):
# 勉強時間の合計 / 勉強した日数を求める
# 勉強時間の合計
total = column.sum()
# 勉強した日数
n = len([x for x in column if x > 0])
return total / n
# 関数を行方向に適用
result_sr = df.apply(calc_mean)
result_srSeriesの要素の合計はsum()で計算できるので、column.sum()で各科目の勉強時間の合計が求められます。
また勉強した日数は、0より大きい要素の数をカウントすることで計算できます。 [x for x in column if x > 0] は、リスト内包表記でcolumnから0より大きい要素だけを抽出したリストを作成しています。このリストの長さをlen()で求めることで、勉強した日数を得られます。
国語 18.50
数学 87.00
理科 33.25
社会 22.00
dtype: float64apply模範解答では、calc_mean()内で「勉強した日数」をカウントする処理を次のように書きました。この方法では、0より大きい要素を抽出したリストを作成し、その長さを求めています。
# 勉強した日数
n = len([x for x in column if x > 0])
これは、次のように簡潔に書くことも可能です。
# 勉強した日数(別解)
n = (column > 0).sum()column > 0 の結果は、columnに格納された列の各要素が0より大きいかどうか判定した結果(Series)になります。たとえばcolumnに列国語が渡された場合は次のようになります。
日付
2022/1/1 True
2022/1/2 False
2022/1/3 True
2022/1/4 True
2022/1/5 True
Name: 国語, dtype: boolsum()はSeriesのメソッドで、Seriesの要素の合計を求めます。Trueは1、Falseは0として集計されるため、 (column > 0).sum()とすることで「0より大きい要素の個数を求める」処理となります。

コメント