

pandasでCSVファイルを読み込むには、read_csv()関数を使います。次のように、第1引数に読み込みたいファイルのパスを指定します。
df = pd.read_csv(ファイルパス)read_csv()にはたくさんのオプションがありますが、デフォルトでは次のように動作します。
- ファイルの1行目を、列名一覧として読み込む
- インデックスは、
0始まりの通し番号を自動で割り振る - 半角カンマ(
,)を区切り文字として認識する

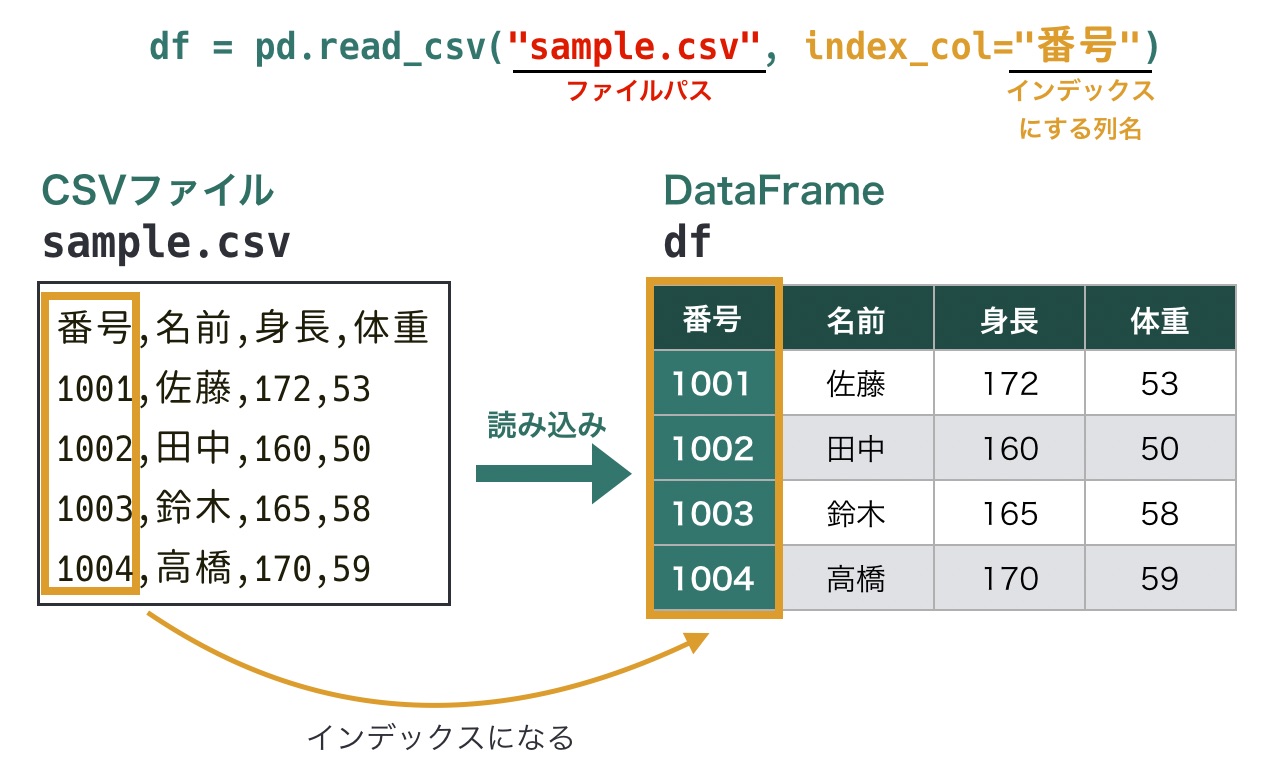
read_csv()にはたくさんのオプションがあります。たとえば、インデックスとなる列を明示的に指定する場合は、引数index_colで列名を指定します。
# インデックスにする列名を指定して読み込み
df = pd.read_csv(ファイルパス, index_col=インデックスにする列名)たとえば、下図のように列番号を指定すると、列番号がインデックスとして設定されます。
演習
さっそく、pandasで読み込みましょう。pandasでCSVファイルを読み込むには、 read_csv()を使います。read_csv()ではさまざまなオプションを引数で指定できますが、まずはデフォルトの設定で読み込んでみましょう。
import pandas as pd
# CSVファイルの読み込み(デフォルト)
df_default = pd.read_csv("dataset/physical_measurement.csv")読み込んだ結果を確認しましょう。read_csv()は、デフォルトでは1行目を列名一覧として読み込みます。また、インデックスは0から始まる通し番号を自動で割り当てます。
df_default| StudentID | Name | Height | Weight | |
|---|---|---|---|---|
| 0 | 1001 | 佐藤 | 172 | 53 |
| 1 | 1002 | 田中 | 160 | 50 |
| 2 | 1003 | 鈴木 | 165 | 58 |
| 3 | 1004 | 高橋 | 170 | 59 |
read_csv()では、さまざまなオプションが用意されています。たとえば、引数index_colで列名を指定すると、指定した列がインデックスとして読み込まれます。
今回は、列StudentIDを指定して実行してみましょう。実行すると、インデックス名が”StudentID”になり、インデックスも1001、1002、1003、1004 に変わっていることがわかります。
# 列StudentIDをインデックスに指定して読み込み
df_with_index = pd.read_csv("dataset/physical_measurement.csv", index_col="StudentID")
df_with_index| Name | Height | Weight | |
|---|---|---|---|
| StudentID | |||
| 1001 | 佐藤 | 172 | 53 |
| 1002 | 田中 | 160 | 50 |
| 1003 | 鈴木 | 165 | 58 |
| 1004 | 高橋 | 170 | 59 |
演習2
import pandas as pd
df = pd.read_csv(
"dataset/exercise_2.txt", index_col="学生番号", sep=" ", encoding="shift_jis"
)
df| 名前 | 身長 | 体重 | |
|---|---|---|---|
| 学生番号 | |||
| 1001 | 佐藤 | 172 | 53 |
| 1002 | 田中 | 160 | 50 |
| 101 | 伊藤 | 166 | 54 |
| 102 | 山本 | 156 | 51 |
今回の問題では、列学生番号をインデックスとして指定して読み込みました。
しかし、型を指定していないので整数として読み込まれてしまい、0101が「文字列の"0101"」ではなく「整数の101」になってしまっています。
列の場合は引数dtypeで型を指定できますが、インデックスの型を指定するオプションはありません。
そのため、インデックスの型を明示的に指定したい場合は、次のステップを踏む必要があります。
- 列のまま、引数
dtypeで型を指定して読み込む - その後、
set_index()を使って列からインデックスに変換する
# 型を指定して読み込み
df = pd.read_csv(
"dataset/exercise_2.csv", sep=" ", encoding="shift_jis", dtype={"学生番号": str}
)
# 列「学生番号」をインデックスに変換
df = df.set_index("学生番号")| 学生番号 | 名前 | 身長 | 体重 |
|---|---|---|---|
| 1001 | 佐藤 | 172 | 53 |
| 1002 | 田中 | 160 | 50 |
| 0101 | 伊藤 | 166 | 54 |
| 0102 | 山本 | 156 | 51 |

コメント