

実務では、分析したいデータは複数のファイルやDBのテーブルに分かれていることが多いです。pandasは、このような複数のデータを統合する機能をいろいろ備えています。
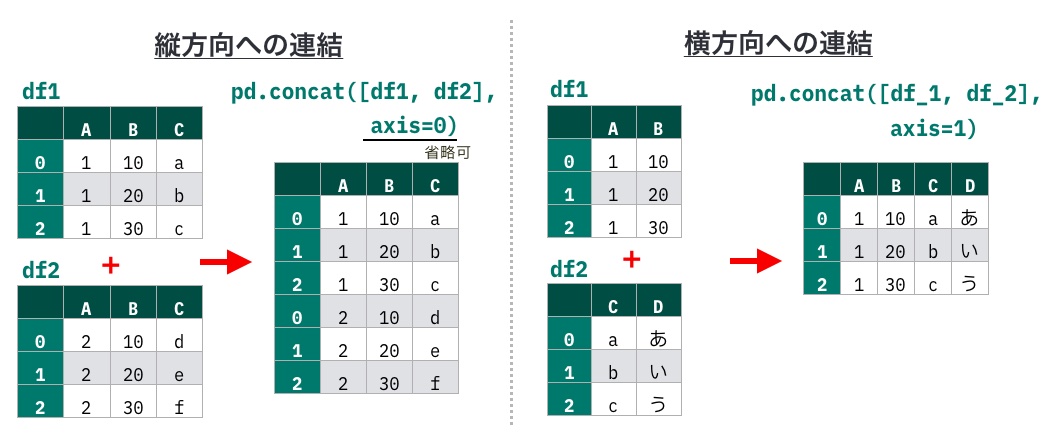
たとえばconcat()を使うと、DataFrameを縦また横方向に連結できます。引数axisで0を指定すると縦方向に、1を指定すると横方向に連結します(デフォルトでは0のため、未指定だと縦方向の連結になります)。
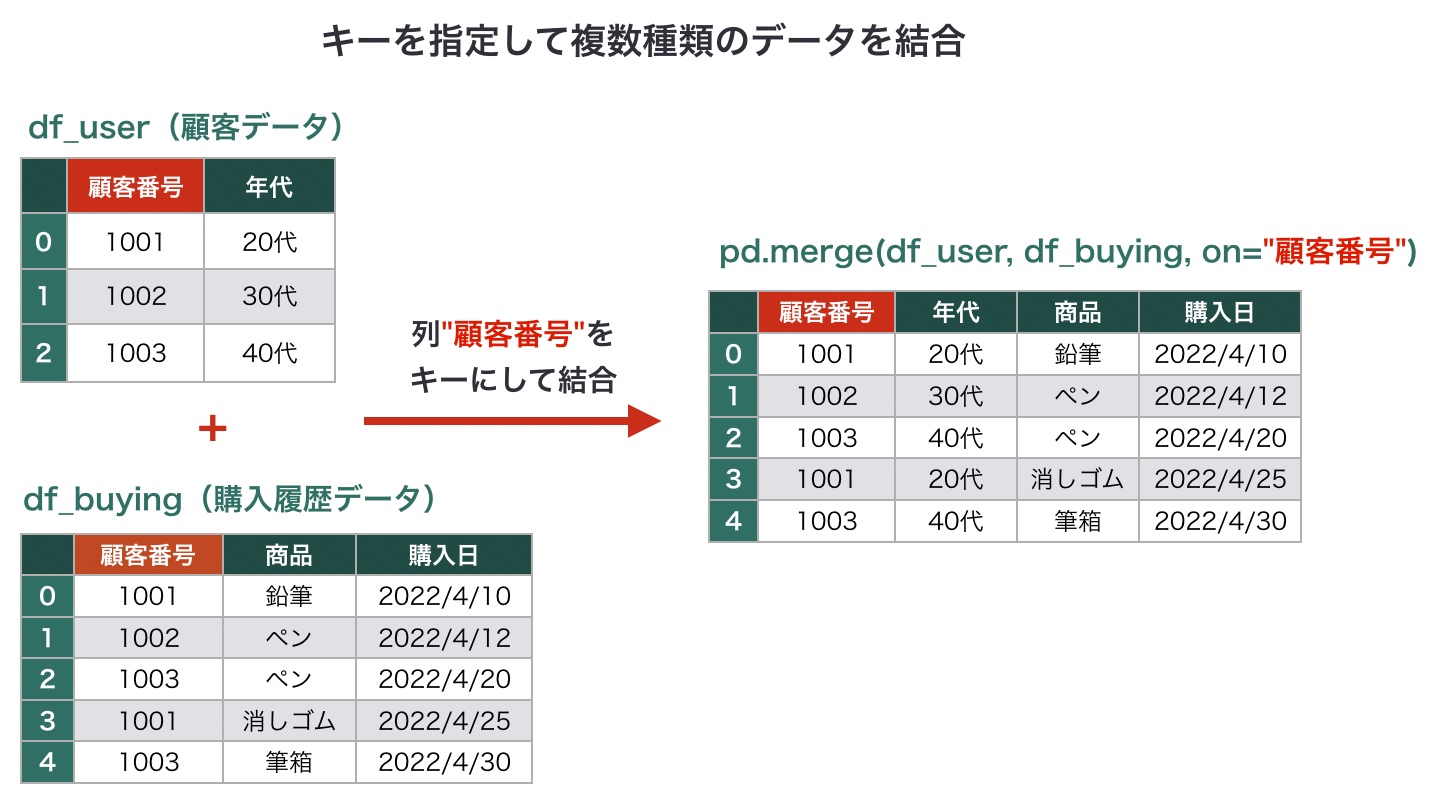
またmerge()を使うと、基準となるキーを指定して複数の種類のデータを結合できます。SQLを知っている方は、JOINのような結合をイメージしてください。
演習
今回は2つのCSVファイルに格納されたデータを扱います。まずは1つ目のCSVファイルを読み込み、変数df_aに格納しましょう。
import pandas as pd
# 1年A組のデータを読み込み
df_a = pd.read_csv("dataset/physical_measurement_A.csv")
df_a| Name | Height | Weight | Club | |
|---|---|---|---|---|
| 0 | 佐藤 | 172 | 53 | 野球部 |
| 1 | 田中 | 160 | 50 | 合唱部 |
| 2 | 鈴木 | 165 | 58 | 美術部 |
1つ目のCSVファイルは”1年A組”の生徒のデータですが、DataFrame内にはクラスの情報が格納されていません。そのため、他のクラスのデータと区別がつくように列Classを追加しましょう。
# 新しい列Classを追加(全ての行に"1年A組"が格納される)
df_a["Class"] = "1年A組"
df_a| Name | Height | Weight | Club | Class | |
|---|---|---|---|---|---|
| 0 | 佐藤 | 172 | 53 | 野球部 | 1年A組 |
| 1 | 田中 | 160 | 50 | 合唱部 | 1年A組 |
| 2 | 鈴木 | 165 | 58 | 美術部 | 1年A組 |
次に、2つ目のファイルを読み込んで変数df_bに格納しましょう。これは”1年B組”のデータですが、先ほどと同様クラスの情報が含まれていないため、同じ手順で列Classを追加します。
# 1年B組のデータを読み込み
df_b = pd.read_csv("dataset/physical_measurement_B.csv")
# 新しい列Classを追加(全ての行に"1年B組"が格納される)
df_b["Class"] = "1年B組"
df_b| Name | Height | Weight | Club | Class | |
|---|---|---|---|---|---|
| 0 | 高橋 | 170 | 59 | 美術部 | 1年B組 |
| 1 | 伊藤 | 166 | 54 | サッカー部 | 1年B組 |
| 2 | 山本 | 156 | 51 | 所属なし | 1年B組 |
| 3 | 渡辺 | 163 | 58 | 所属なし | 1年B組 |
df_aとdf_bを連結して、1つのDataFrameにまとめましょう。pd.concat(DataFrameが格納されたリスト)を実行すると、引数で指定した複数のDataFrameを縦方向に連結できます。axis=0は省略可
# df_aとdf_bを連結して、1つのDataFrameにする
df_concat = pd.concat([df_a, df_b])
df_concat| Name | Height | Weight | Club | Class | |
|---|---|---|---|---|---|
| 0 | 佐藤 | 172 | 53 | 野球部 | 1年A組 |
| 1 | 田中 | 160 | 50 | 合唱部 | 1年A組 |
| 2 | 鈴木 | 165 | 58 | 美術部 | 1年A組 |
| 0 | 高橋 | 170 | 59 | 美術部 | 1年B組 |
| 1 | 伊藤 | 166 | 54 | サッカー部 | 1年B組 |
| 2 | 山本 | 156 | 51 | 所属なし | 1年B組 |
| 3 | 渡辺 | 163 | 58 | 所属なし | 1年B組 |
連結前と連結後の行数を確認しましょう。連結前のdf_aが3行5列、df_bが4行5列であるのに対し、この2つを連結したdf_concatは7行5列であることがわかります。
print(df_a.shape) # 連結前の行数・列数(1)
print(df_b.shape) # 連結前の行数・列数(2)
print(df_concat.shape) # 連結後の行数・列数(3, 5) (4, 5) (7, 5)
df.reset_index(drop=True)をするとインデックスを治すことが出来る。

コメント